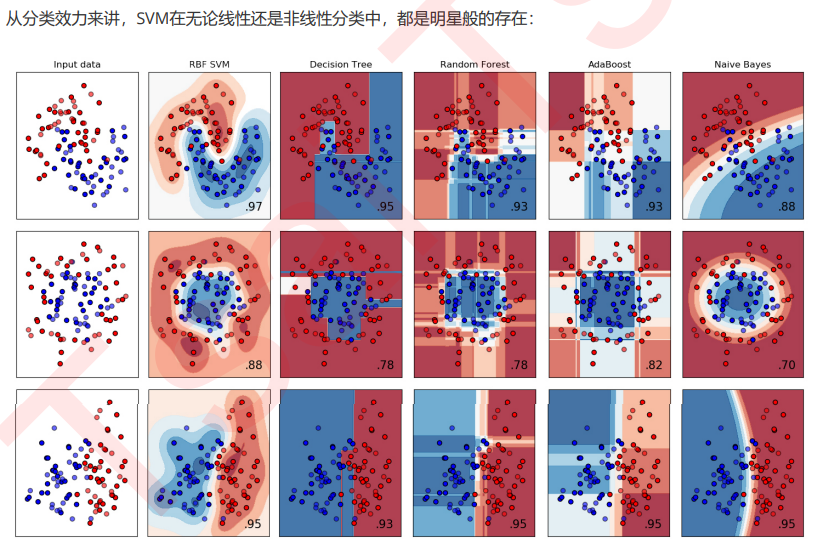
支持向量机的分类方法,是在这组分布中找出一个超平面作为决策边界,使模型在数据上的 分类误差尽量接近于小,尤其是在未知数据集上的分类误差(泛化误差)尽量小。

决策边界一侧的所有点在分类为属于一个类,而另一侧的所有点分类属于另一个类。如果我们能够找出决策边界, 分类问题就可以变成探讨每个样本对于决策边界而言的相对位置。比如上面的数据分布,我们很容易就可以在方块 和圆的中间画出一条线,并让所有落在直线左边的样本被分类为方块,在直线右边的样本被分类为圆。如果把数据 当作我们的训练集,只要直线的一边只有一种类型的数据,就没有分类错误,我们的训练误差就会为0。
但是,对于一个数据集来说,让训练误差为0的决策边界可以有无数条。