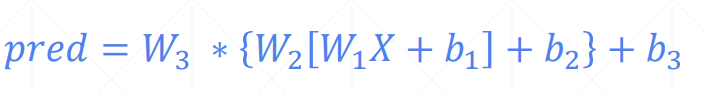
Non-linear Factor
加入激活函数之后

pred既有线性表达能力,还有非线性的表达能力



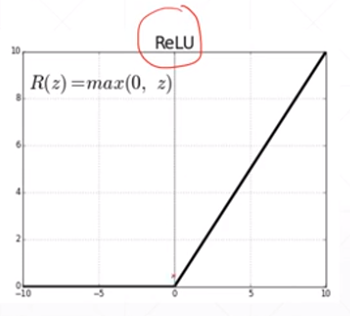
Non-linear Factor
加入激活函数之后
pred既有线性表达能力,还有非线性的表达能力
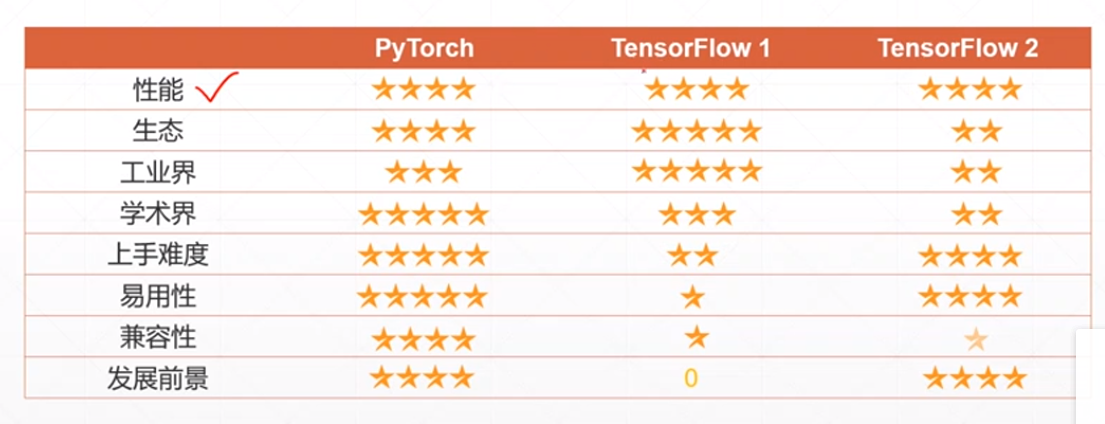
pytorch的功能:
(1)CPU加速;
没有显卡,用不了cuda
(2)自动求导*非常重要,因为深度学习本质上就是在利用梯度下降法来求最优解;
(3)常用网络层


静态图:
define——>run
在最开始就需要定义好公式,给定输入值,得到输出值,而且在运行的过程中无法进行调整

动态图:
可以随时调整公式
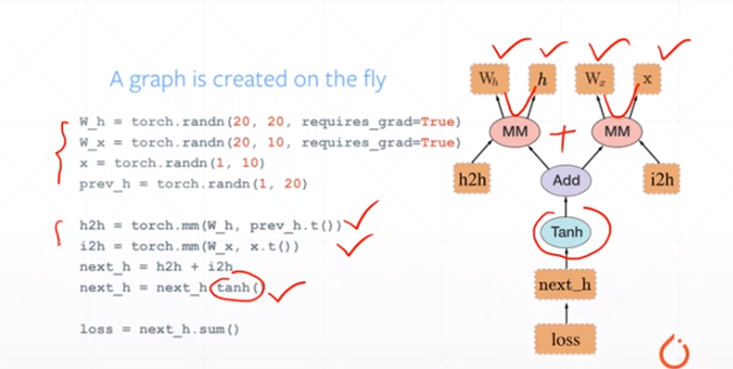
linear Regression——我们要估计连续函数的值;
logistic Regression——在上述linear regression的基础上增加了一个激活函数,把y的空间压缩到0-1的范围,0-1可以表示一个概率
classification——所有的可能性概率之和为1
数据降维
1.特征选择
2.主成分分析
MinMaxScaler(feature_range=())
feature_range 可以指定在一定的数值范围内
tf idf
tf:term frenquency词的频率 出现的次数
idf:inverse document frequency 逆文档频率
log(总文档数量/该词出现的文档数量)
重要性程度
countvectorizer没有参数
文本都是放在列表里面的可迭代对象
性能瓶颈,读取速度
格式不太符合机器学习要求数据的格式
可用数据集:
Kaggle
UCI
scikit-learn
机器学习是从数据中自动分析获得规律(模型),并利用规律对未知数据进行预测
1. 解放生产力
2.解决专业问题
3.提供社会便利
梯度下降法
让机器学习程序替换手动步骤,减少企业的成本,也提高企业的效率
真是听过讲的最烂的,重点yong'yuan'tiao'guo
# Machine learning
- make decisions
- go right/left
- increse/decrease
# 为什么使用tensorflow
- GPU加速 比cpu快很多
- 自动求导
- 神经网络API
> 给与cpu和gpu一个热身的时间:warm-up
# 非监督学习
## k-means (聚类)
> 聚类做在分类之前
# 分类算法:逻辑回归
> 逻辑回归:线性回归的式子作为输入,解决二分类问题, 也可以得出概率值
## 1、应用场景(基础分类问题:二分类)
- 广告点击率
- 是否为垃圾邮件
- 是否患病
- 金融诈骗
- 虚假账号
## 2、广告点击
- 点击
- 没点击
## 3、逻辑回归的输入与线性回归相同
# 模型的保存和加载
from sklearn.externals import joblib
## 过拟合与欠拟合
> 问题:训练集数据训练得很好,误差也不大,在测试集上有问题 原因:学习特征太少,导致区分标准太粗糙,不能准确识别处目标
- 欠拟合:特征太少
- 过拟合:特征过多
特征选择:
- 过滤式:低方差特征
- 嵌入式: 正则化,决策树,神经网络
## 2、线性回归策略
> 预测结果与真实值有误差
> 回归:迭代的算法,知道误差,不断减小误差,
### 损失函数
- 最小二乘法之梯度下降
scikit-learn:
- 优点:封装好,建立模型简单,预测简单
- 缺点:算法的过程,有些参数都在算法API内部优化