1.Python程序由模块构成。每个模块以.py结束。
2.CTRL+s保存内容。
3.tab默认四个空格。
4.勤写注释。
5.使用\行连接符(一行代码太长)


1.Python程序由模块构成。每个模块以.py结束。
2.CTRL+s保存内容。
3.tab默认四个空格。
4.勤写注释。
5.使用\行连接符(一行代码太长)
import turtle
turtle.width(10)
turtle.color("blue")
turtle.circle(50)
turtle.penup()
turtle.goto(120,0)
turtle.pendown()
turtle.color("black")
turtle.circle(50)
turtle.penup()
turtle.goto(240,0)
turtle.pendown()
turtle.color("red")
turtle.circle(50)
turtle.penup()
turtle.goto(60,-50)
turtle.pendown()
turtle.color("yellow")
turtle.circle(50)
turtle.penup()
turtle.goto(180,-50)
turtle.pendown()
turtle.color("green")
turtle.circle(50)
1.python是一种解释型、面向对象的语言。
import turtle
turtle.showturtle() #显示箭头
turtle.write("fuzhuoming") #写字符串
turtle.forward(300)#前进300
turtle.color("red") #画笔颜色变红
turtle.left(90)
turtle.forward(300)
turtle.goto(0,50)
turtle.goto(0,0)
turtle.penup()#抬笔
turtle.goto(0,300)
turtle.pendown()
turtle.goto(0,50)
turtle.goto(50,50)
turtle.circle(100)
1.IDE:集成开发环境
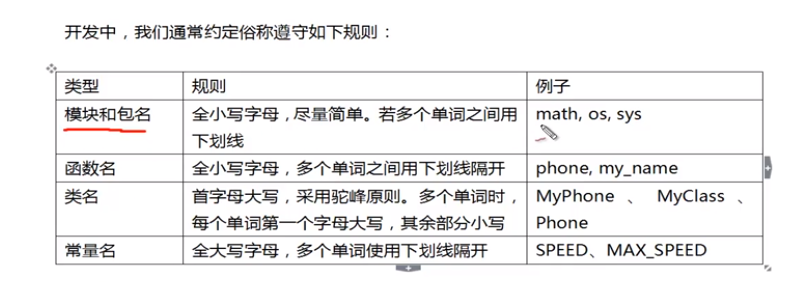
开发中,各类名称的定义
e
偏移量包头不包尾
float(3)=3.0
float("3.14")=3.14
id+type(类型)+value(值)=对象
eg: 3 id:1531372336 type:int value:3
a:1531372336 #把地址赋给a
变量必须先被初始化,不然不能运行。eg:ddd 是不能运行会报错的。
F1快捷键,找出python的API
\ ——用于换行,也叫行连接符。
#序列化
import pickle#引入pickle模块
a1="蜡笔小新"
a2=234
a3=[10,20,30,40]
#把上面的内容添加一个二进制文件中
with open("data.dat","wb") as f:
pickle.dump(a1,f)
pickle.dump(a2,f)
pickle.dump(a3,f)
#现在是乱码状态,下面开始转换成可读的内容
with open("data.dat","rb") as f:
b1=pickle.load(f)
b2=pickle.load(f)
b3=pickle.load(f)
#打印出来
print(b1);print(b2);print(b3)
#测试a1是否于b1相等
print(id(a1));print(id(b1))
#不相等
蜡笔小新
234
[10, 20, 30, 40]
1617878845360
1617920883280
#读取和写入CSV文件
#引入CSV模块
import csv
#打开文件,注意:如果乱码,请在最后标明encoding的类型
with open("efg.csv","r",encoding='utf-8') as f:
a_csv=csv.reader(f)#读出文件内容
# print(list(a_csv))
for row in a_csv:#用循环读出文件内容
print(row)
#打开一个新的文件
with open("ee.csv","w") as f:
#获得一个写入器
b_csv=csv.writer(f)
#一行一行的写
b_csv.writerow(["ID","姓名","年龄"])
b_csv.writerow(["1001","工藤新一","17"])
c=[["1002","希希","18"],["1003","黑羽快斗","16"]]
b_csv.writerow(c)
['\ufeffID', '姓名', '年龄', '破案量']
['1001', '工藤新一', '17', '1000']
['1002', '服部平次', '18', '200']
['1003', '黑羽快斗', '16', '100']
ID,姓名,年龄
1001,工藤新一,17
"['1002', '希希', '18']","['1003', '黑羽快斗', '16']"
with open("e.txt","r",encoding="utf-8") as f:#打开文件
print("文件名是:{0}".format(f.name))#打印文件名
print(f.tell())#返回文件中指针的当前位置
print("读取内容:{0}".format(str(f.readline())))#读取文件的第一行
print(f.tell())#返回文件中指针的当前位置
print("读取内容:{0}".format(str(f.readline())))#读取文件的第二行
print(f.tell())#返回文件中指针的当前位置
递归算法
1.定义递归头
2.递归体
def fact(n):
if n==1:
return n
else:
return n*fact(n-1)
print(fact(5))
import shutil
shutil.make_archive('电影/gg','zip','movie/港台')
import zipfile
z1=zipfile.ZipFile('d:/a.zip','w')
z1.write('1.txt')
z1.write('1_copy.txt')
z.clost()
z2=zipfile.ZipFile('d:/a.zip','r')
z2.extractall('电影')
import shutil
shutil.copyfile('1.txt','1_copy.txt')
shutil.copytree('movie/港台','电影')
import os
path=os.getcwd()
list_files=os.walk(path)
for dirpath,dirnames,filenames in list_files:
for dir in dir names:
print(dir)