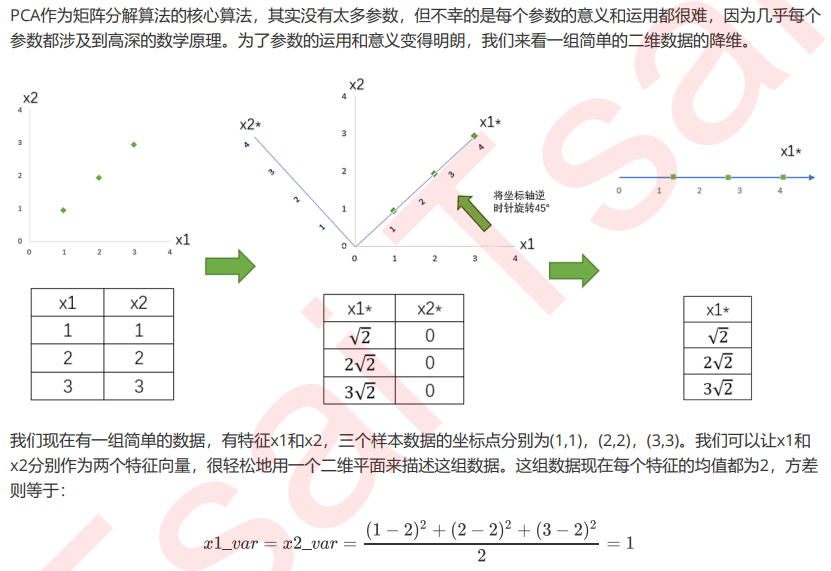
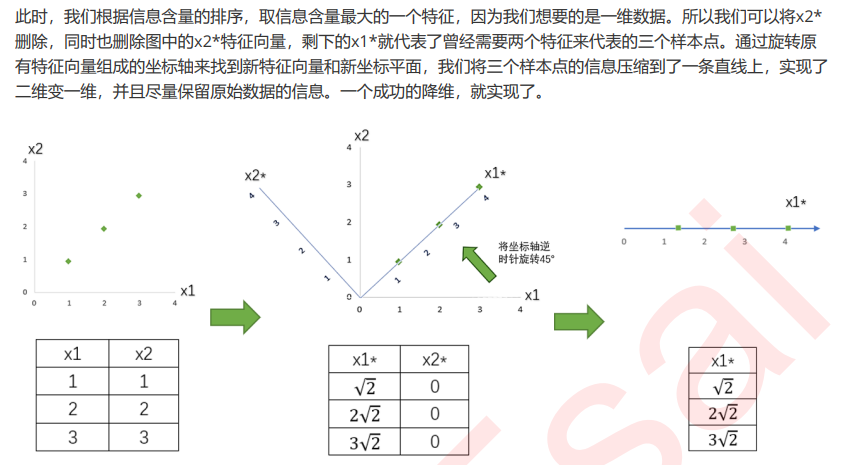
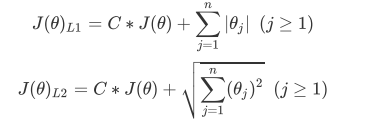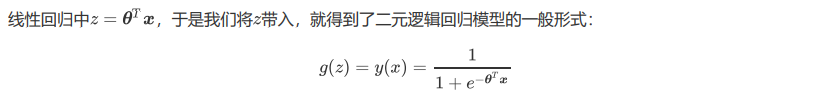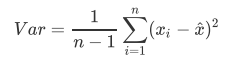业务选择
说到降维和特征选择,首先要想到的是利用自己的业务能力进行选择,肉眼可见明显和标签有关的特征就是需要留 下的。当然,如果我们并不了解业务,或者有成千上万的特征,那我们也可以使用算法来帮助我们。或者,可以让 算法先帮助我们筛选过一遍特征,然后在少量的特征中,我们再根据业务常识来选择更少量的特征。
PCA和SVD一般不用
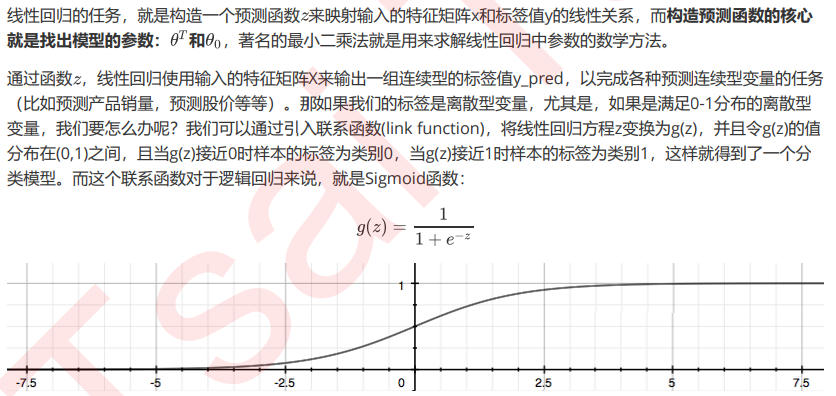
逻辑回归是由线性回归演变而来,线性回归的一个核心目的是通过求解参数来探究特征X与标签y之间的 关系,而逻辑回归也传承了这个性质,我们常常希望通过逻辑回归的结果,来判断什么样的特征与分类结果相关, 因此我们希望保留特征的原貌。PCA和SVD的降维结果是不可解释的,因此一旦降维后,我们就无法解释特征和标 签之间的关系了。当然,在不需要探究特征与标签之间关系的线性数据上,降维算法PCA和SVD也是可以使用的。
统计方法可以使用,但不是非常必要
逻辑回归对数据的要求低于线性回归,由于我们不是使用最小二乘法来求解,所以逻辑回归对数据的总体分布和方差没有要求,也不需要排除特征之间的共线性,但如果我 们确实希望使用一些统计方法,比如方差,卡方,互信息等方法来做特征选择,也并没有问题。过滤法中所有的方法,都可以用在逻辑回归上。