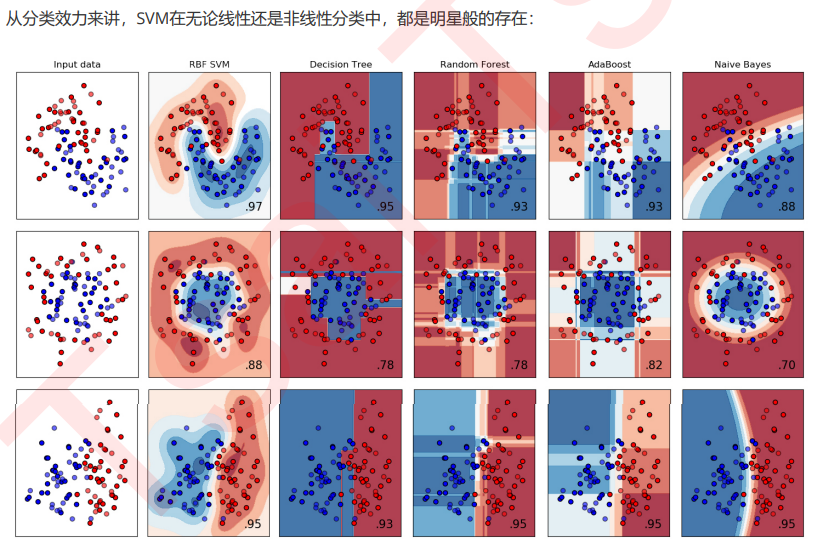
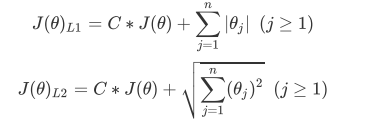hist 直方图
from matplotlib import pyplot as plt
from matplotlib import font_manager
a=[zifuchuan]
plot.hist(a.fenzushu)
细节
计算组数=num_bin= (max(a)-nim(b)//d)
d=5
组数= 极差/组距
x轴的刻度设置
plt.xticks(range(min(a),max(a)+d,d))
plt.show()
图形大小:plt.figure(figsze=(20,8),dpi=80)
{数据}