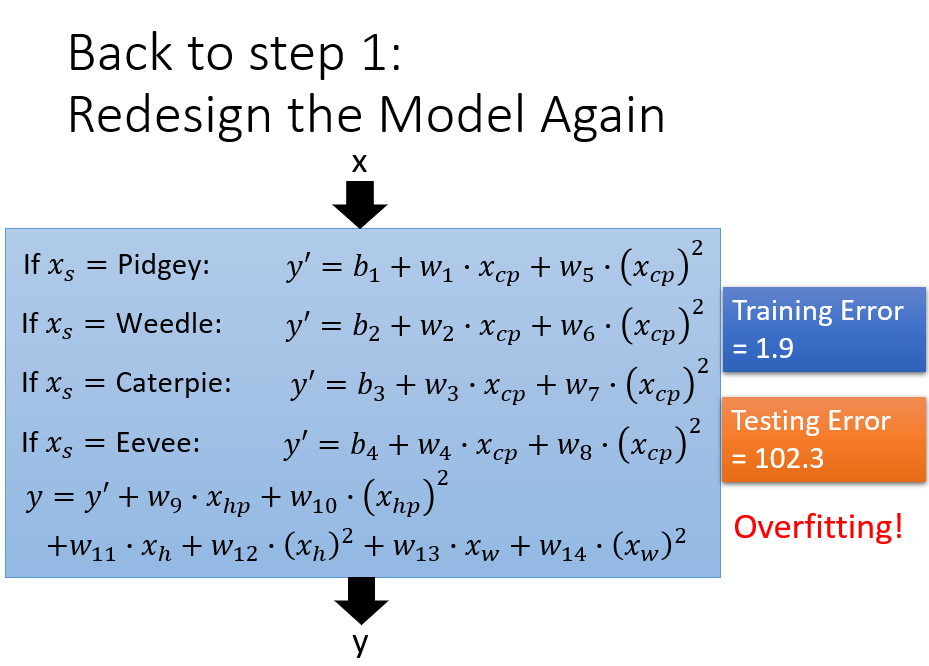
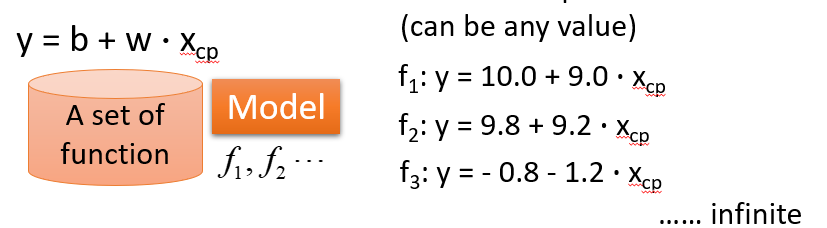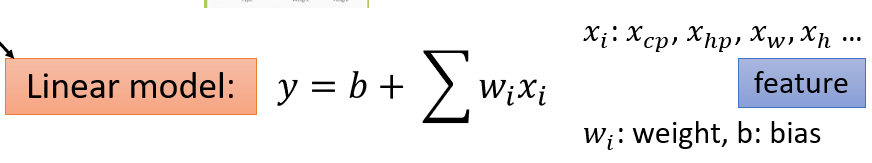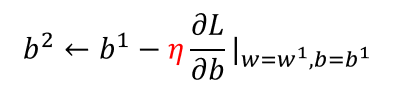Gradient Descent

Gradient:loss损失函数等高线的发现方向
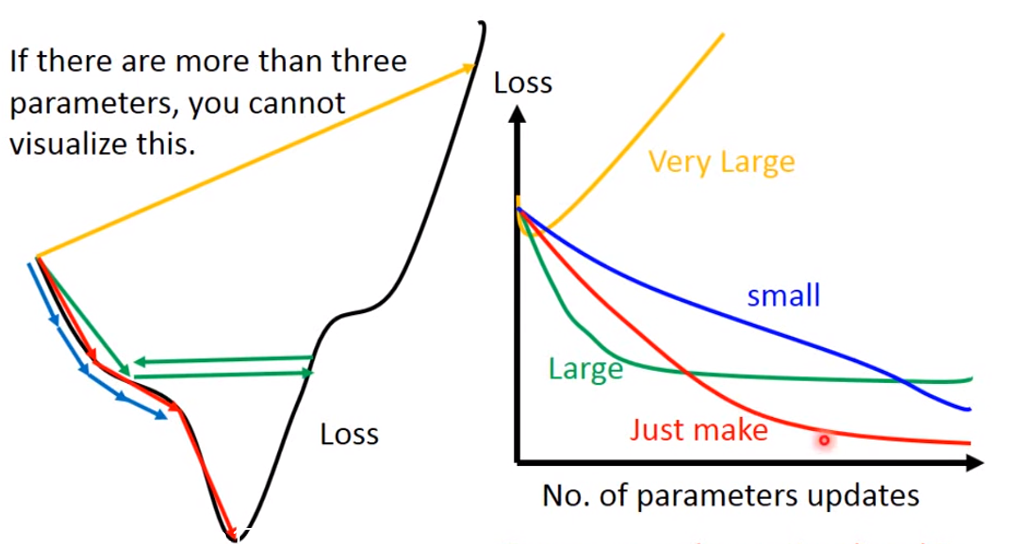
需要注意的是:learning rate 需要设置合理
如果learning rate很小,loss下降的很慢;
如果learning rate表达大,可能卡住,找不到loss的极小值;
如果learning rate非常大,loss有可能越来越大
只有当learning rate 刚刚好的时候,我们才能得到loss的极小值
Adagrad
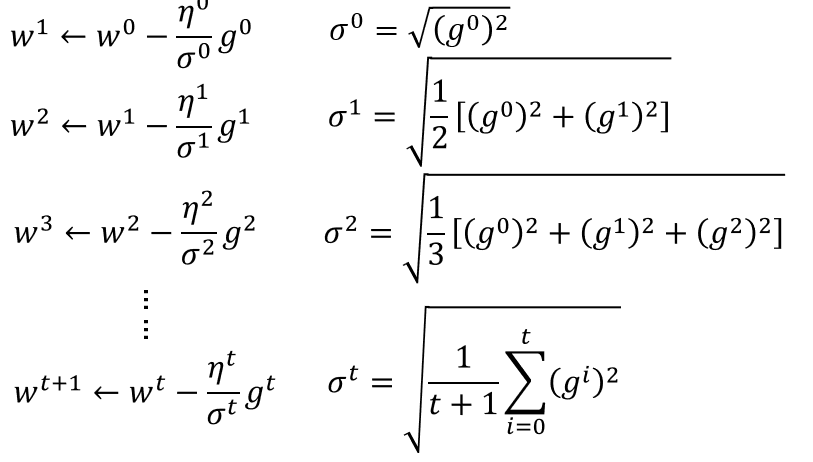
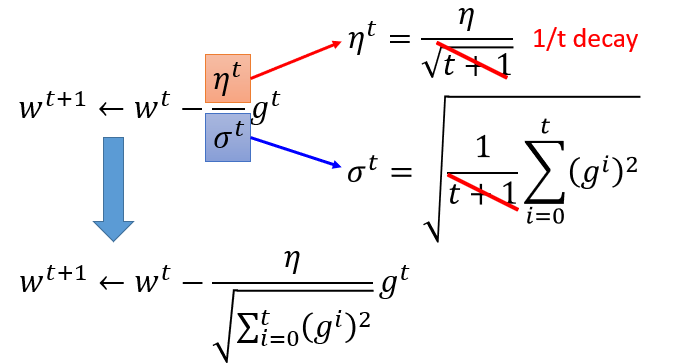
有个矛盾点是,对于gt来说,梯度越大,w参数应该下降得越快,但是分母上也有g的和,分母越大,w参数值下降得越小,这里应该如何理解?

对于2次函数来说,可以直观的看出Adagrad的优势
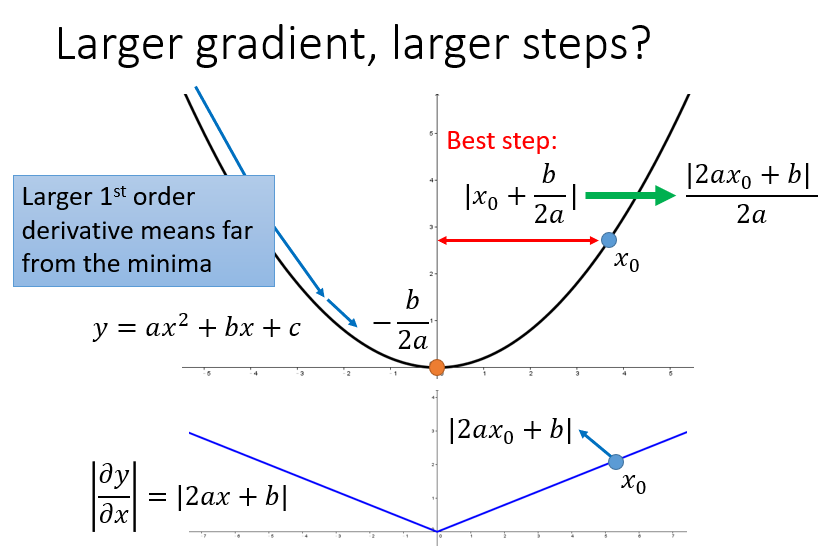
最好的步长是一阶导的绝对值除以二阶导的值
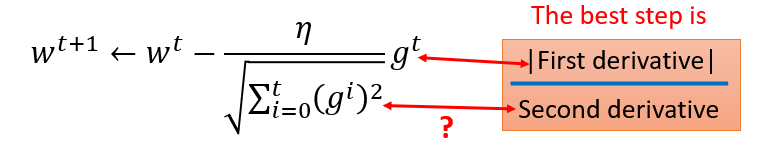
这里的分母虽然是一阶导的绝对值的和,但在一定程度上可以看出二阶导的大小来
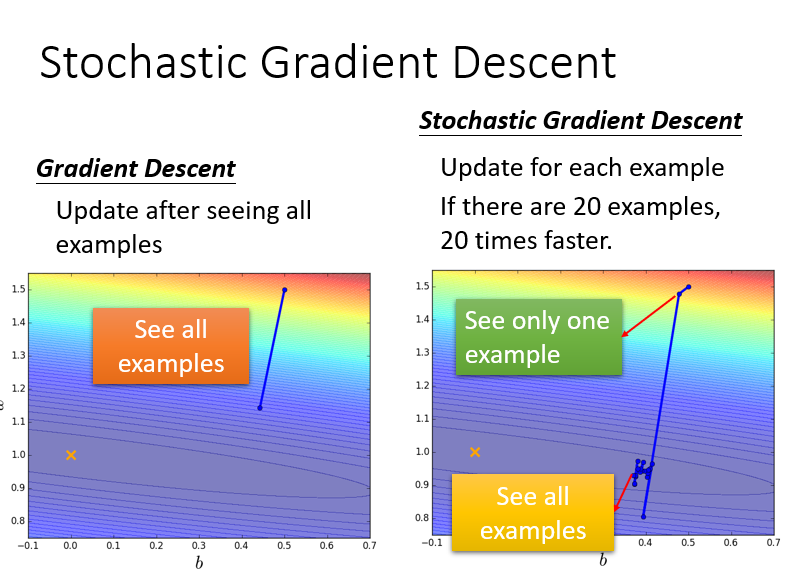
Stochastic Gradient Descent
只看一个example,只考虑一个点的参数值(其实没听懂)
Feature Scaling
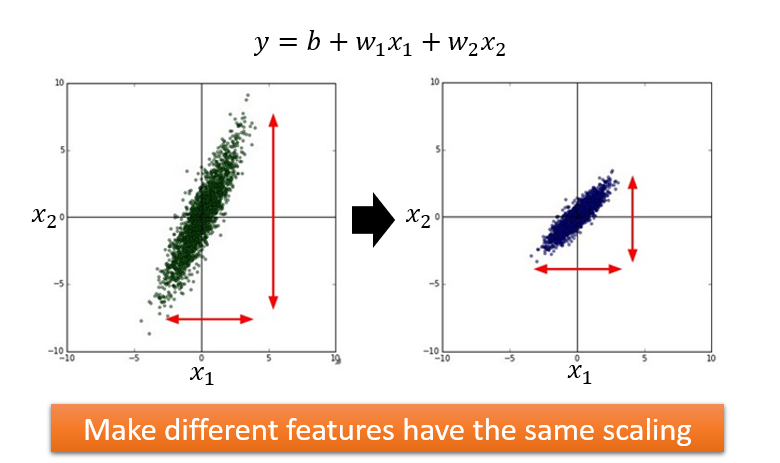
做法:

梯度下降背后的数学原理
泰勒定理:

多元的情况下: