选择结构
单分支选择结构
条件表达式详解
在选择和循环结构中,条件表达式的值为False的情况如下:
False、0、0.0、空值None、空序列对象


选择结构
单分支选择结构
条件表达式详解
在选择和循环结构中,条件表达式的值为False的情况如下:
False、0、0.0、空值None、空序列对象
Embedded嵌入法
嵌入法是一种让算法自己决定使用哪些特征的方法,即特征选择和算法训练同时进行。在使用嵌入法时,我们先使 用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大到小选择特征。这些权值系数往往代表了特征对于模型的某种贡献或某种重要性,比如决策树和树的集成模型中的feature_importances_属性,可以列出各个特征对树的建立的贡献,我们就可以基于这种贡献的评估,找出对模型建立最有用的特征。
过滤法中使用的统计量可以使用统计知识和常识来查找范围(如p值应当低于显著性水平0.05),而嵌入法中使用 的权值系数却没有这样的范围可找——我们可以说,权值系数为0的特征对模型丝毫没有作用,但当大量特征都对 模型有贡献且贡献不一时,我们就很难去界定一个有效的临界值。
嵌入法引入了算法来挑选特征,因此其计算速度也会和应用的算法有很大的关系。如果采用计算量很大,计 算缓慢的算法,嵌入法本身也会非常耗时耗力。并且,在选择完毕之后,我们还是需要自己来评估模型。
先使用方差过滤,然后 使用互信息法来捕捉相关性,不过了解各种各样的过滤方式也是必要的。
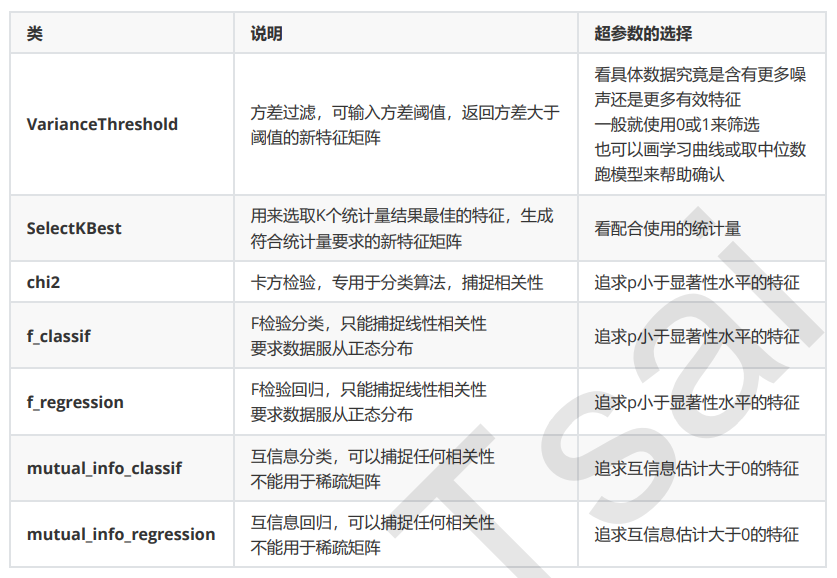
互信息法是用来捕捉每个特征与标签之间的任意关系(包括线性和非线性关系)的过滤方法。和F检验相似,它既 可以做回归也可以做分类,并且包含两个类feature_selection.mutual_info_classif(互信息分类)和 feature_selection.mutual_info_regression(互信息回归)。这两个类的用法和参数都和F检验一模一样,不过 互信息法比F检验更加强大,F检验只能够找出线性关系,而互信息法可以找出任意关系。
集合:无序可变,集合底层是字典实现,集合的所有元素都是字典中的”键对象“,因此是不能重复且唯一的。
集合创建和删除
1.{}创建
2.set()创建
3.remove()、clear()
集合相关操作
字典核心底层原理(重要)
列表通过索引值寻找,字典通过键寻找。
字典对象的核心是散列表。散列表是一个稀疏数组,数组的每个单元叫做bucket,每个bucket有两部分:一个是键对象的引用,一个是值对象的引用。
(1)将一个键值对放进字典的底层过程
序列解包
序列解包可以用于元组、列表、字典。序列解包可以方便对多个变量进行赋值。
字典元素添加、修改、删除
1.给字典新增键值对,如果键已经存在则被覆盖,若键不存在则增加。
2.使用update()将新字典中所有键值对全部添加到旧字典上,如果键重复则进行覆盖。
3.字典中元素的删除,可以使用del()方法,或者clear()删除所有键值对;pop()删除指定键值对,并返回对应的值对象。
4.popitem():随机删除和返回键值对,字典是无序可变序列,因此没有元素的排序顺序等;popitem弹出随机的项。
字典元素的访问
(1)通过【键】获得“值”
(2)通过get()方法获得值(推荐使用)
字典
字典是“键值对”的无序可变序列,字典中的每个元素都是一个“键值对”,包含:"键对象"和“值对象”。可以通过“键对象”实现快速获取,删除,更新对应的“值对象”。“键”不可重复。
字典的创建
(1)通过{},dict()函数创建字典。
(2)zip()
(3)通过fromkeys创建值为空的字典
生成器推导式创建元组
生成器推导式生成的不是列表也不是元组,而是一个生成器对象。
元组的元素访问和计数
元组排序
zip():将多个列表对应位置的元素组合成为元组,并返回这个zip对象。
元组tuple
列表属于可变序列,可以任意修改列表中的序列。元组属于不可变序列,不能修改元组中的元素。所以,元组中没有增加元素,修改元素,删除元素相关的方法。
元组的创建
(1)通过()创建,小括号可以省略。
(2)通过tuple()创建元组。将字符串,range()序列,列表转化为元组。
元组的删除
多维列表
二维列表
列表的排序
(1)修改源列表,不建立新列表
a.sort()
(2)建新列表的排序
a=sorted(a)
(3)reversed()返回迭代器
隐马可夫链,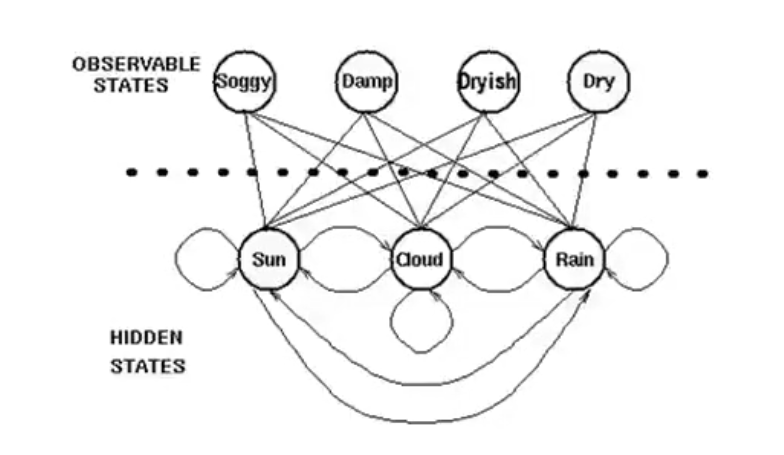
期望不能反映收益,
切片操作
[起始偏移量:终止偏移量:步长]
列表的遍历
列表元素访问和计数
(1)通过索引直接访问元素
(2)获得指定元素在列表中首次出现的索引
index(value,[start,end])
(3)count()获得指定元素在列表中出现的次数
(4)len()列表长度
列表元素的删除
(1)del删除
a=[100,200,888,300,400] del(a[2]) print(a)
本质上是数组元素依次拷贝
(2)pop()方法
a=[10,20,30,40,50] b=a.pop() print(b) #50a中元素从末尾依次弹出 c=a.pop(1) print(c) #20弹出指定元素 print(a) #[10, 30, 40]a中元素被弹出后
(3)remove():删除首次出现的指定元素。
a=[10,20,30,40,50] a.remove(20) print(a) #[10, 30, 40, 50]
处理连续型特征:二值化和分箱
根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量。大于阈值的值映射为1,而小于或等于阈 值的值映射为0。默认阈值为0时,特征中所有的正值都映射到1。
二值化是对文本计数数据的常见操作,分析人员 可以决定仅考虑某种现象的存在与否。它还可以用作考虑布尔随机变量的估计器的预处理步骤(例如,使用贝叶斯 设置中的伯努利分布建模)。
分箱
