python不适用的场景为效率性能要求较高的场景。c/go/java/c++都比他性能高。


3289-顾同学-人工智能学科-计算机视觉方向
3289-顾同学-人工智能学科-计算机视觉方向
![]() 扫二维码继续学习 二维码时效为半小时
扫二维码继续学习 二维码时效为半小时
for 遍历所有数值
print(输出便利数值)
for x in 数值
print()
海龟绘图我pycharm无法输出
- 不要在程序中,行开头处增加空格,空格在py中含有缩进的意义
- 符号是英文符号
关键字,不能作为变量名,使用help()查看关键字,变量以字母或者下划线开头,后接字母下划线数字
回归>>>均方误差MSE
随机森林>>>分类器比较好用吗?
random_state是不同的特征作为初始的节点来产生的不同的树,所以需要不同的特征
袋装法,有放回的随机抽样技术
n个样本组成的自助集
bootstrap>>默认为True
袋外数据(out of bag data,简写为oob)
criterion 不纯度的衡量指标
有基尼系数和信息熵,信息熵的增益
n_estimators 这是森林中树木的数量,基评估器的数量,default-10
实例化-交叉验证
波动本质上是一样的, 但集成算法压倒性的强
集成算法
调参曲线,交叉验证,网格算法 调参方法
base estimator 基评估器
boosting 结合弱评估器一次次对难以评估的对象进行攻克
对特征提问得出决策规则-决策树
字符串的变量
可用 == 和 is 来判断是否是同个id
只有包含下划线字母数字的字符才能进入驻留,特殊符号不可以,所以id会发生变化。
字符串成员操作符: in , not in
1.split(x) 以'x'为界限分割字符串 x可以是空格,单字符,多字符
2.‘x’.join(y) y中的字符串,以x为分隔,拼接成一个大字符串
使用【:】取字符串的片段
[:]:取全部
[2:]从第三个位置到最后
[2:5]从第三个位置到第五个位置 注:包头不包尾
[1:5:x] 在位置1:5之间每隔x取一个
也可以用'-'号进行反向取值,同样包头不包尾
[::-1],反向排
1.str() 注:转化数据为字符串
2.通过[]提取字符串 注:第一个字符为0,最后一个字符为len(str)-1,既可以正向提取,也可以反向向提取
3.replace在字符串中的应用
例:a = 'xy'
a.replace('x','y')
print(a)
输出: 'yy'
1.转义符号的使用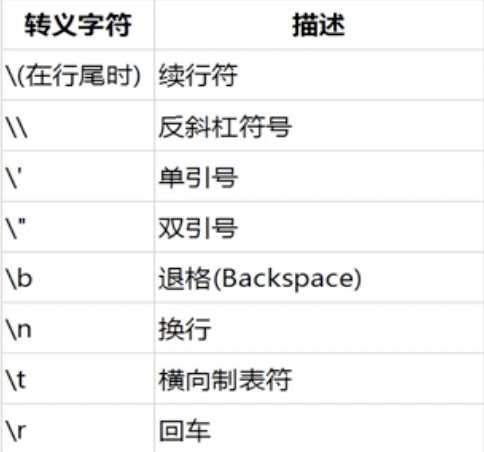
2.字符串可通过+进行拼接操作(需两个为字符串)
3.字符串可通过*号进行复制
4.通过end=“”,来避免换行
使用 input()从控制台读取键盘输入内容
myname = input('请输入名字:')
请输入名字:x
print(myname)
输出 'x'
1.同一运算符:is ,is not
区别:is判断的是地址
==判断的是值
注:在-5,256之间数值会缓存,所以id是相同的,不同解释器不同
1.布尔值本质是1和0
2.布尔值的比较运算符:等于,不等于,大于,小于,大于等于,小于等于
返回:True和False
3.逻辑运算符:或or,与and,非not
https://cloud.189.cn/t/EBF
### sys.path和模块搜索路径
按下面的顺序从上往下搜索
1.内置模块
2.当前目录
3.程序的主目录
4.Pythonpath目录(如果已经设置Pythonpath环境变量)
5.标准链接库目录
6.第三方库目录
7..pth文件的内容(如果存在的话)
8.sys.path.append()临时添加的目录
### 包的本质和init文件——批量导入
__init__.py的三个核心作用:
1.作为包的标识,不能删除
2.用来实现模糊导入
3.导入包实质是执行__init__.py文件,可以在__init__.py文件中做这个包的初始化,以及需要统一执行代码,以及批量导入
### 用*导入包
import*会把子模块全部导入,生产中不建议使用
### 包内引用
from..importmodule_a #..表示上级目录
from.import module_A2 #.表示同级目录
##包的内容
### 导入包操作
导入和使用时要写上包名
#import my01.aa.module.A #from my01.aa.module.A import fun_aa