fsfada


3234-陈一苇-人工智能学科-数据挖掘方向-就业:是
3234-陈一苇-人工智能学科-数据挖掘方向-就业:是
![]() 扫二维码继续学习 二维码时效为半小时
扫二维码继续学习 二维码时效为半小时
#apply返回每个测试样本所在叶子节点的索引
clf.apply(xtext)
#predict返回每个测试样本的分类、回归结果
clf.predict(xtest)
特征函数与中心极限定理没看懂
#决策树 # from sklearn import tree#导入需要的模块 # clf=tree.DecisionTreeClassifier()#实例化 # clf=clf.fit(x_train,y_train)#用训练集数据训练模型 # result=clf.score(x_test,y_test)#导入测试集,从接口中调用需要的信息进行打分
citerion:不纯度,不纯的越低,训练集拟合越好
机器学习
贝叶斯学派
逆概率
pxy = px * py 独立
若不独立
条件概率
P(x|y) = P(xy) /P(y)
支持向量机的分类方法,是在这组分布中找出一个超平面作为决策边界,使模型在数据上的 分类误差尽量接近于小,尤其是在未知数据集上的分类误差(泛化误差)尽量小。

决策边界一侧的所有点在分类为属于一个类,而另一侧的所有点分类属于另一个类。如果我们能够找出决策边界, 分类问题就可以变成探讨每个样本对于决策边界而言的相对位置。比如上面的数据分布,我们很容易就可以在方块 和圆的中间画出一条线,并让所有落在直线左边的样本被分类为方块,在直线右边的样本被分类为圆。如果把数据 当作我们的训练集,只要直线的一边只有一种类型的数据,就没有分类错误,我们的训练误差就会为0。
但是,对于一个数据集来说,让训练误差为0的决策边界可以有无数条。
支持向量机(SVM,也称为支持向量网络),是机器学习中获得关注最多的算法没有之一。它源于统计学习理论, 是我们除了集成算法之外,接触的第一个强学习器。它有多强呢?

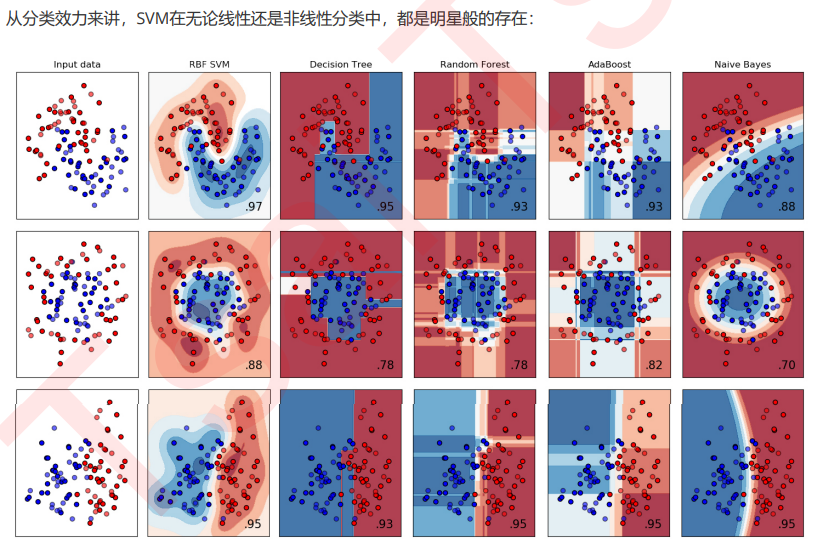
从实际应用来看,SVM在各种实际问题中都表现非常优秀。它在手写识别数字和人脸识别中应用广泛,在文本和超 文本的分类中举足轻重,因为SVM可以大量减少标准归纳(standard inductive)和转换设置(transductive settings)中对标记训练实例的需求。同时,SVM也被用来执行图像的分类,并用于图像分割系统。。除此之外,生物学和许多其他科学都是SVM的青睐者,SVM现在已经广泛被用于蛋白质分类,现 在化合物分类的业界平均水平可以达到90%以上的准确率。在生物科学的尖端研究中,人们还使用支持向量机来识 别用于模型预测的各种特征,以找出各种基因表现结果的影响因素。
从学术的角度来看,SVM是最接近深度学习的机器学习算法。线性SVM可以看成是神经网络的单个神经元(虽然损 失函数与神经网络不同),非线性的SVM则与两层的神经网络相当,非线性的SVM中如果添加多个核函数,则可以 模仿多层的神经网络。
高效嵌入法embedded
业务选择
说到降维和特征选择,首先要想到的是利用自己的业务能力进行选择,肉眼可见明显和标签有关的特征就是需要留 下的。当然,如果我们并不了解业务,或者有成千上万的特征,那我们也可以使用算法来帮助我们。或者,可以让 算法先帮助我们筛选过一遍特征,然后在少量的特征中,我们再根据业务常识来选择更少量的特征。
PCA和SVD一般不用
逻辑回归是由线性回归演变而来,线性回归的一个核心目的是通过求解参数来探究特征X与标签y之间的 关系,而逻辑回归也传承了这个性质,我们常常希望通过逻辑回归的结果,来判断什么样的特征与分类结果相关, 因此我们希望保留特征的原貌。PCA和SVD的降维结果是不可解释的,因此一旦降维后,我们就无法解释特征和标 签之间的关系了。当然,在不需要探究特征与标签之间关系的线性数据上,降维算法PCA和SVD也是可以使用的。
统计方法可以使用,但不是非常必要
逻辑回归对数据的要求低于线性回归,由于我们不是使用最小二乘法来求解,所以逻辑回归对数据的总体分布和方差没有要求,也不需要排除特征之间的共线性,但如果我 们确实希望使用一些统计方法,比如方差,卡方,互信息等方法来做特征选择,也并没有问题。过滤法中所有的方法,都可以用在逻辑回归上。
重要参数penatly&C
1、正则化

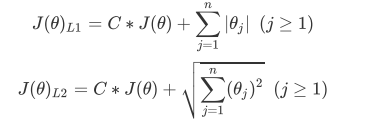

L1正则化和L2正则化虽然都可以控制过拟合,但它们的效果并不相同。当正则化强度逐渐增大(即C逐渐变小), 参数的取值会逐渐变小,但L1正则化会将参数压缩为0,L2正则化只会让参数尽量小,不会取到0。
在L1正则化在逐渐加强的过程中,携带信息量小的、对模型贡献不大的特征的参数,会比携带大量信息的、对模型 有巨大贡献的特征的参数更快地变成0,所以L1正则化本质是一个特征选择的过程,掌管了参数的“稀疏性”。L1正 则化越强,参数向量中就越多的参数为0,参数就越稀疏,选出来的特征就越少,以此来防止过拟合。
相对的,L2正则化在加强的过程中,会尽量让每个特征对模型都有一些小的贡献,但携带信息少,对模型贡献不大 的特征的参数会非常接近于0。通常来说,如果我们的主要目的只是为了防止过拟合,选择L2正则化就足够了。但 是如果选择L2正则化后还是过拟合,模型在未知数据集上的效果表现很差,就可以考虑L1正则化。


为什么需要逻辑回归
1. 逻辑回归对线性关系的拟合效果好到丧心病狂,特征与标签之间的线性关系极强的数据,比如金融领域中的 信用卡欺诈,评分卡制作,电商中的营销预测等等相关的数据,都是逻辑回归的强项。虽然现在有了梯度提 升树GDBT,比逻辑回归效果更好,也被许多数据咨询公司启用,但逻辑回归在金融领域,尤其是银行业中的 统治地位依然不可动摇(相对的,逻辑回归在非线性数据的效果很多时候比瞎猜还不如,所以如果你已经知 道数据之间的联系是非线性的,千万不要迷信逻辑回归);
2. 逻辑回归计算快:对于线性数据,逻辑回归的拟合和计算都非常快,计算效率优于SVM和随机森林,亲测表示在大型数据上尤其能够看得出区别;
3. 逻辑回归返回的分类结果不是固定的0,1,而是以小数形式呈现的类概率数字:我们因此可以把逻辑回归返 回的结果当成连续型数据来利用。比如在评分卡制作时,我们不仅需要判断客户是否会违约,还需要给出确 定的”信用分“,而这个信用分的计算就需要使用类概率计算出的对数几率,而决策树和随机森林这样的分类 器,可以产出分类结果,却无法帮助我们计算分数(当然,在sklearn中,决策树也可以产生概率,使用接口 predict_proba调用就好,但一般来说,正常的决策树没有这个功能)。
另外,逻辑回归还有抗噪能力强的优点。福布斯杂志在讨论逻辑回归的优点时,甚至有着“技术上来说,最佳模型 的AUC面积低于0.8时,逻辑回归非常明显优于树模型”的说法。并且,逻辑回归在小数据集上表现更好,在大型的 数据集上,树模型有着更好的表现。
由此,我们已经了解了逻辑回归的本质,它是一个返回对数几率的,在线性数据上表现优异的分类器,它主要被应 用在金融领域。其数学目的是求解能够让模型对数据拟合程度最高的参数 的值,以此构建预测函数 ,然后将 特征矩阵输入预测函数来计算出逻辑回归的结果y。注意,虽然我们熟悉的逻辑回归通常被用于处理二分类问题, 但逻辑回归也可以做多分类。
重要接口inverse_transform
神奇的接口inverse_transform,可以将我们归一化,标准化,甚至做过哑变 量的特征矩阵还原回原始数据中的特征矩阵,这几乎在向我们暗示,任何有inverse_transform这个接口的过程都 是可逆的。PCA应该也是如此。
而逻辑回归,是一种名为“回归”的线性分类器,其本质是由线性回 归变化而来的,一种广泛使用于分类问题中的广义回归算法。要理解逻辑回归从何而来,得要先理解线性回归。线 性回归是机器学习中最简单的的回归算法,它写作一个几乎人人熟悉的方程:
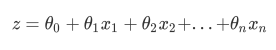
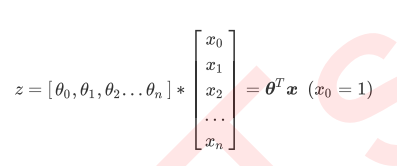
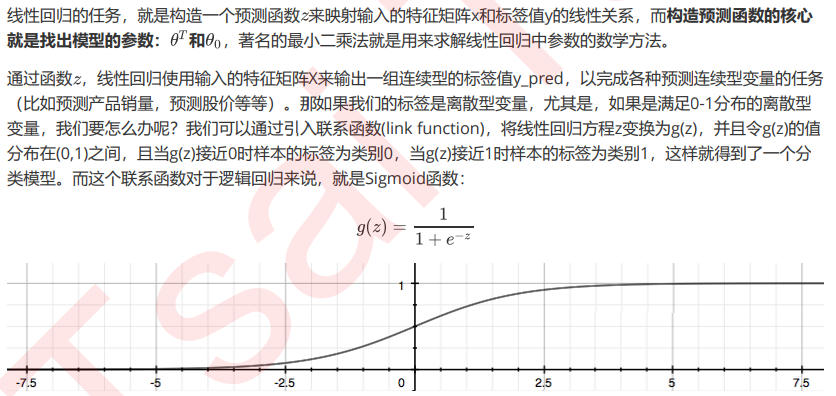

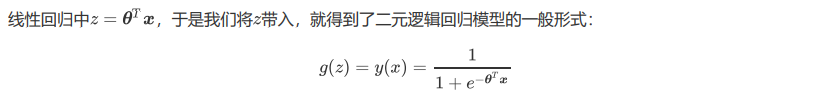


特征选择:方差过滤
```python
from sklearn.feature_selection import VarianceThreshold #特征选择,根据方差进行过滤
def var():
'''
特征选择-选择低方差的特征
:return:None
'''
var=VarianceThreshold(threshold=1.0)#保留方差值为1的数值
data=var.fit_transform([[0,2,0,3],[0,1,4,3],[0,1,1,3]])#三行四列的二维数组
print(data)
return None
if __name__=='__main__': #调用
var()
```
PCA:主成分分析
把维度降低,但是数据信息尽可能不损耗

文本特征分类功能:
1、文本特征抽取:count
文本分类----如每天的文献分类/文章的分类
2、tf idf:
2.1 tf:term frequency:词的频率 出现的次数(类似count)
2.2 idf:逆文档频率inverse document frequency
log(总文档数量/该词出现的文档数量)
例:log(数值):输入的数值越小,结果越小
tf*idf 重要性
文本特征抽取:Count
功能:
文本分类
情感分析
默认对于单个英文字母或者单词:没有不统计
词组分类器:jie'ba
特征抽取:特征值化
字典数据特征抽取:对字典数据进行特征值化
DictVectorizer语法:
字典数据抽取:将字典中的一些类别数据,分别转换成一些数值。
数组形式:有类别的这些特征,先要转换字典数据