列表切片操作
典型操作
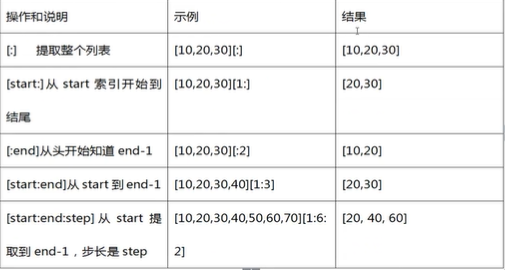
切片不在范围内也不会报错。起始偏移量小于0则会被当成0,终止偏移量大于长度-1则会被当成长度-1
列表遍历
for obj in listObj:
print(obj)


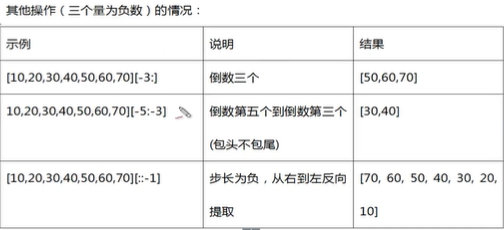
列表切片操作
典型操作
切片不在范围内也不会报错。起始偏移量小于0则会被当成0,终止偏移量大于长度-1则会被当成长度-1
列表遍历
for obj in listObj:
print(obj)
梯度下降法
生成器推导式创建元组
生成器推导式用的小括号。生成器生成生成器对象,再转化成元组。
s=(x*2 for x in range(5))
print(tuple(s)) #只能访问一次元素,第二次就为空了。需要再生成一次。
print(s._next_()) #指针下移
元组可以作为字典的键,列表不行。
元组的元素访问和计数
1. 元组的元素不能修改
2.访问和列表一样,返回的仍然是元组
3.如果要对元组排序,只能用sorted()生成新的列表对象
Zip
将多个列表对应位置的元素组合成为元组,并返回这个zip对象。
元组tuple
可以修改列表中的元素,元组属于不可变序列。
元组支持如下操作:
1. 索引访问
2. 切片操作
3. 连接操作
4. 成员关系操作
5. 比较运算操作
6. 计数
元组的创建
1.通过()
a =(10,20,30) #小括号可以省略
a=(20,) #单元素加逗号
2.通过tuple()
b=tuple(可迭代的对象)
元组对象删除 del b
多维列表
二维列表
一维列表帮助存储一维、线性的数据。
二维列表帮助存储二维、表格的数据。
a=[
['高一',18,3000,'北京']
['高二',17,2000,'上海']
['高三',19,1000,'深圳']
]
print(a[0][3])
嵌套循环打印二维列表的所有数据
a=[
['高一',18,3000,'北京']
['高二',17,2000,'上海']
['高三',19,1000,'深圳']
]
for m in range(3):
for n in range(4):
print(a[m][n],end='\t')
print()#打印完一行,换行
列表排序
修改原列表,不生成新列表的排序
a=[40,10,20,30]
a.sort() #默认升序
a.sort(reverse=True) #降序排列
import random
random.shuffle(a) #随机打乱顺序
建新列表的排序
内置函数sorted(),这个方法返回新列表,不对原列表修改
a=[40,10,20,30]
a=sorted()
c=sorted(a,reverse=True)
reversed()返回迭代器
内置函数reversed()也支持逆序排列,不对原列表做修改。
max和min
返回列表中的最大最小值
sum
对数值型列表所有列表求和,非数值型报错

误差来源于两个——一个是bias,还有一个是variance。出现bias是由于开始就没有瞄准靶心;出现vaiance是由于瞄准了靶心,但是发射的时候出现了偏离。我们的目标是低bias和低variance。
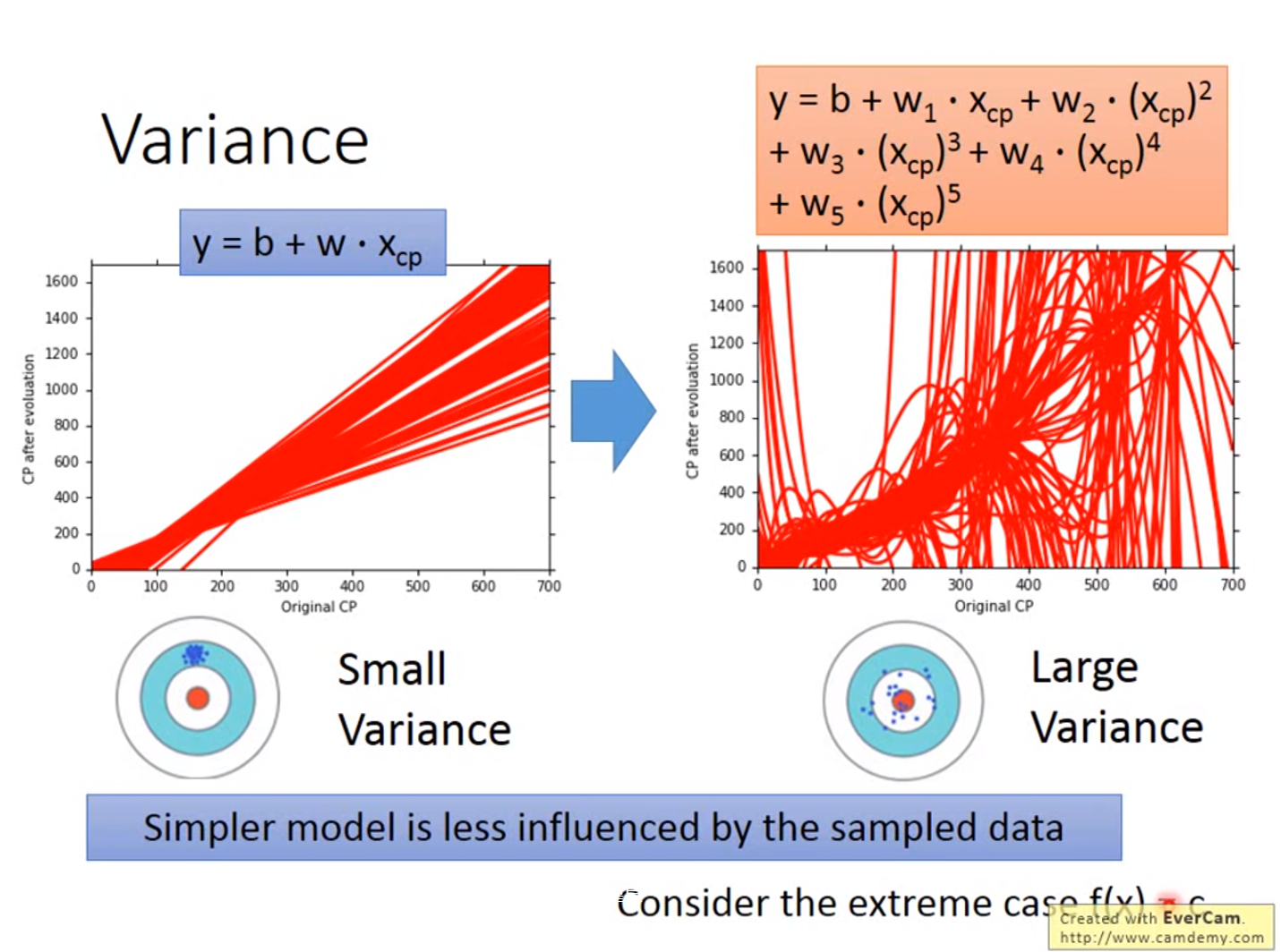
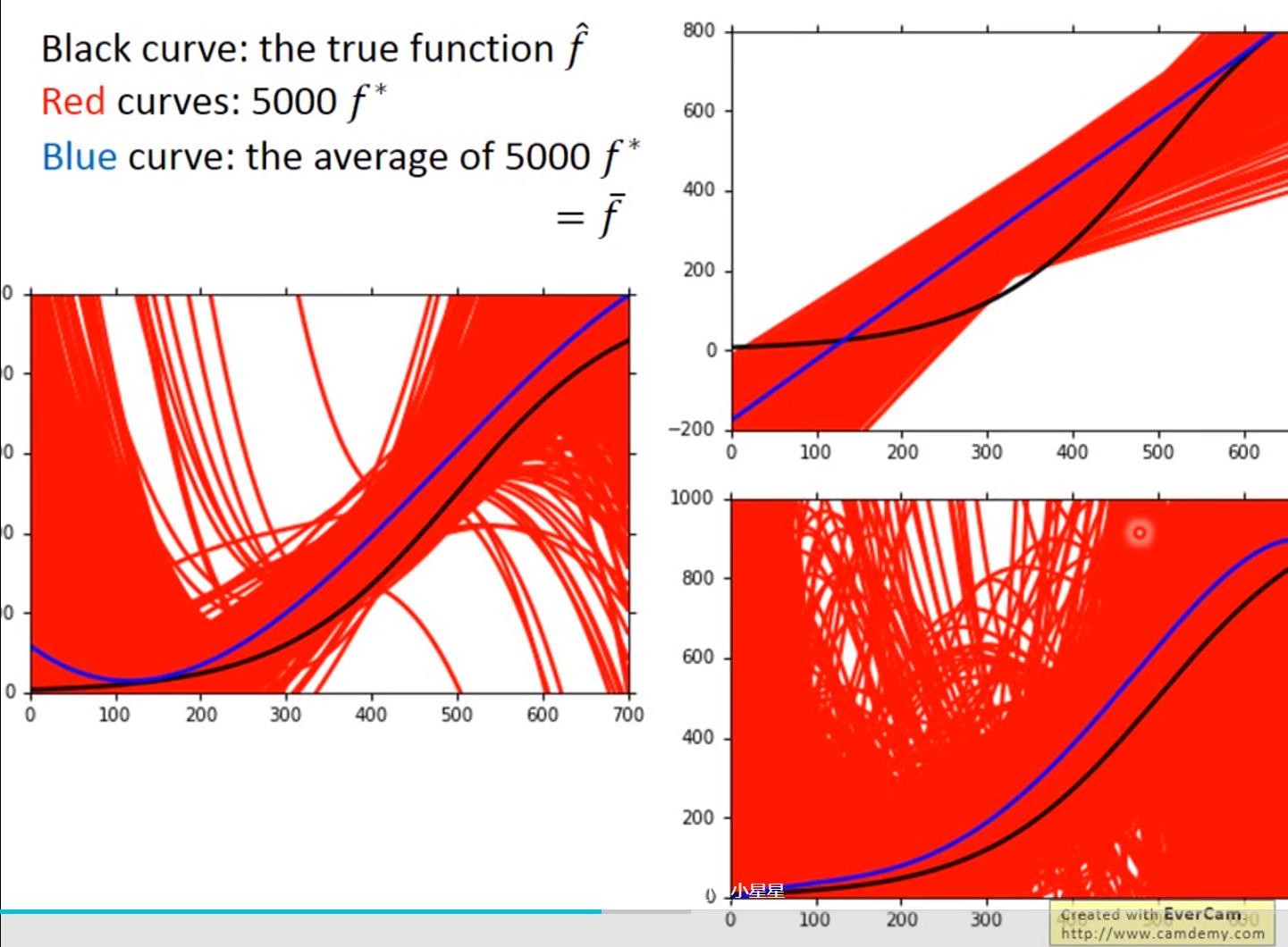
红色的部分是分别在考虑输入值一次方、三次方和五次方函数进行5000次实验的结果,蓝色的线条是将5000次实验结果进行平均即结果
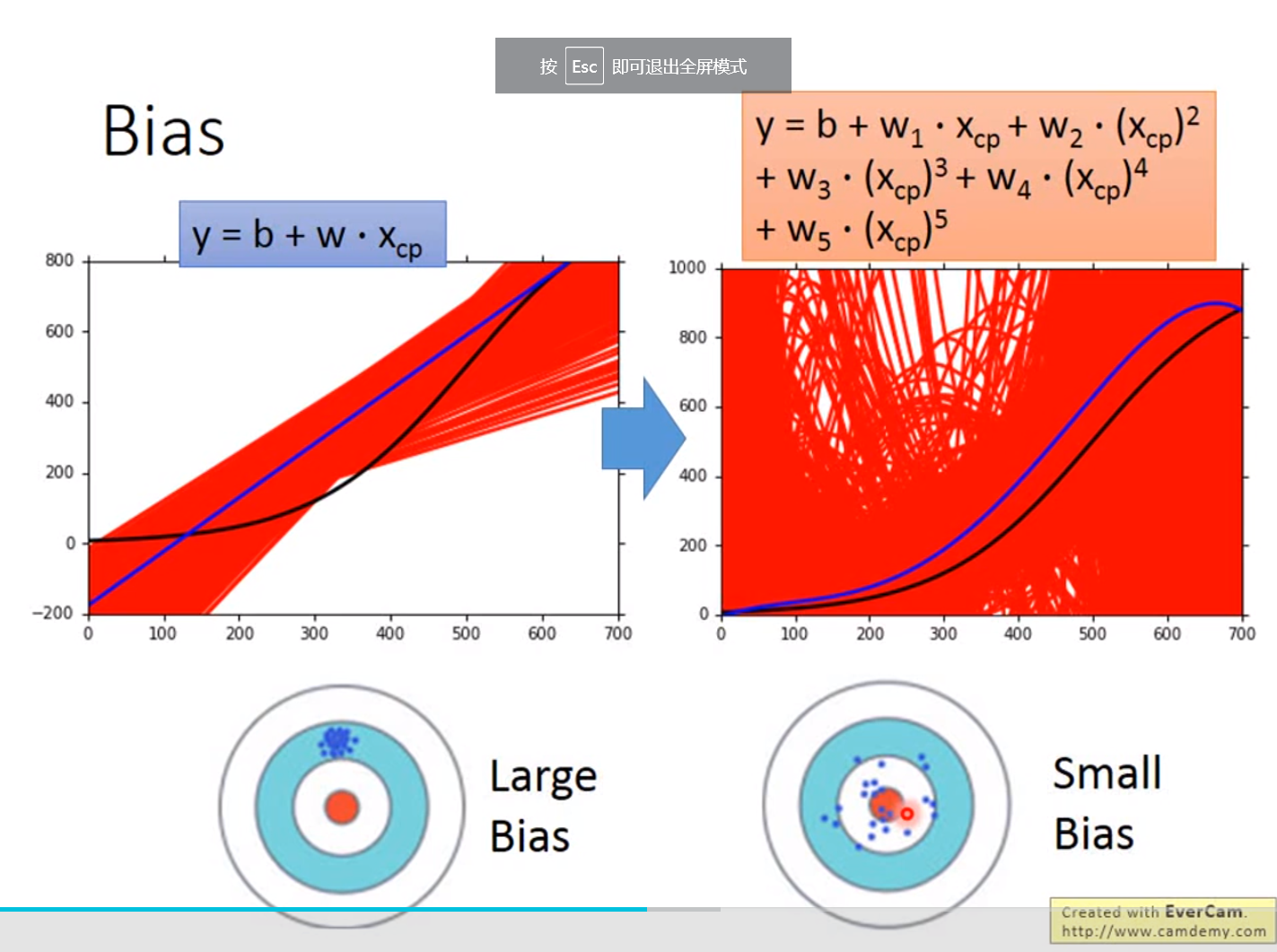

越简单的模型,bias越大,variance比较小;反之,模型越复杂,variance越大,但是平均值却比较接近于期望值
bias较大的情况,问题出现在underfitting;
variance较大的情况,问题出现在overfitting
Diagnosis:
(1)当模型不能拟合训练集时,我们有较大的bias;
(2)当模型可以集合训练集,但是在测试集上出现了较大的损失值,则很大可能上有较大的variance
for bias, redesign模型:
(1)add more feature as input
(2)a more complex model
for variance
(1)more data(增加每次实验的样本量)
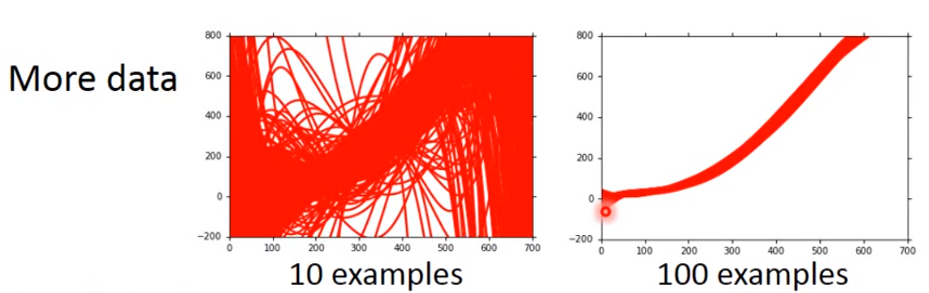
(2)Regularization我们希望曲线越平缓越好

伤害:只包含了比较平滑的曲线,在取值上产生了较大的bias
model selection:
我们想要找到尽可能小的bias和variance来得到最小的损失值
列表元素访问和计数
通过索引直接访问元素
索引区间[0,列表长度-1],超过范围则报错
index()获得指定元素在列表中首次出现的索引
index(value,[start,[end]])
a=[10,20,30,40,50]
a.index(50,3)
count()获得指定元素在列表中出现的次数
a=[10,20,30,20,50]
a.count(20)
len()返回列表长度
列表中元素的个数
成员资格判断
in关键字判断
a=[10,20,30,40,50]
20 in a
列表元素的删除
del删除
删除列表指定位置的元素
a=[10,20,30]
del a[1]
print(a)
pop()方法
pop()删除并返回指定位置元素,如果未指定位置则默认操作列表最后一个位置
a=[10,20,30]
b=a.pop()
print(b)
remove()方法
删除首次出现的指定元素,不存在则异常
Regression回归
1、应用场景
(1)Stock Market Forecast
(2)Self-driving Car
(3)Recommendation
2、步骤
(1)给一个Model
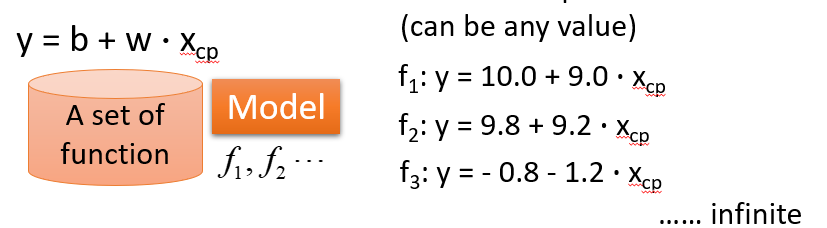
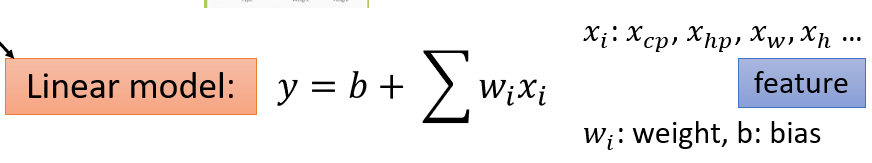
(2)Goodness of Function(函数优度)
输入:a function一个函数
输出:loss funchtion——how bad it is
 Pick the “Best”Function
Pick the “Best”Function
(3)Gradient Descent
梯度下降:初试化w和b这两个参数,不断迭代更新,知道找到最优解,也就是使损失值达到最小的参数值

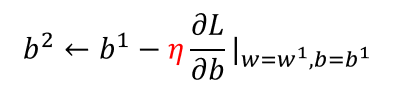
在线性回归里,是不需要担心找不到全局最优解的,因为其三维图形是一圈一圈的等高线,不管从哪个方向都可以找到最优解
how's the results?
训练的目的是损失值最小,但是通过训练集得到的损失值是比测试集得到的损失值小的,为了减少误差,我们需要改进模型——引入了二次方、三侧方和四次方的函数
overfitting——更复杂的模型会得到更不好的结果,所以模型并不是越复杂越好。
what are the hidden factors——pokemon的物种会影响他们值


根据不同的输入值,对不同的物种设置不同 的权重,此时仅设置了输入值的一次方,还可以考虑输入值的二次方函数
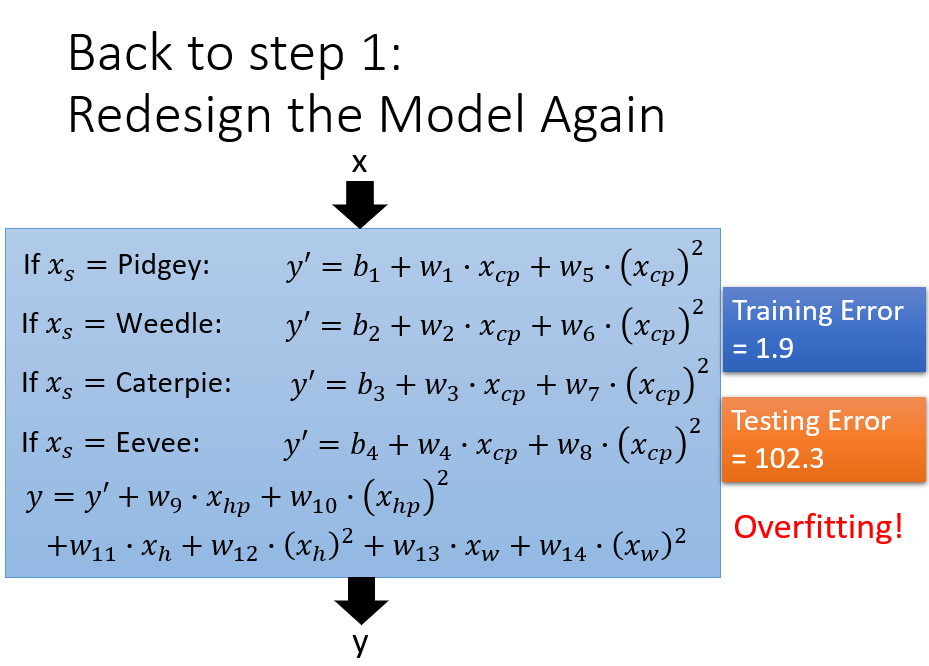
产生了过拟合的结果

设置较为平缓的曲线,由于w的值大于零小于1,当其越接近于0,结果是越为平缓的,前面的系数越大,代表我们越考虑smooth,越可以较多得关注参数w本身的值
列表的创建
基本语法[]创建
a=[]
list()创建
list可以将任何可迭代的数据转变成列表
a=list('zifuchuan')
range()创建整数参数
range([start,]end[,step])
start可选,表示起始数字,默认0
end必选,表示结尾数字
step可选,表示步长,默认1
推导式生成列表
a=[x*2 for x in range(5)] #循环创建多个元素
a=[x*2 for x in range(100) if x%9==0] #通过if过滤元素
1.比较运算符可以连用
3<a<10
2.位操作
&=按位与
|=按位或
^=按位异
<<左移1位相当于乘以2;左移两位相当于乘以4
>>右移1位相当于除以2;右移两位相当于除以4
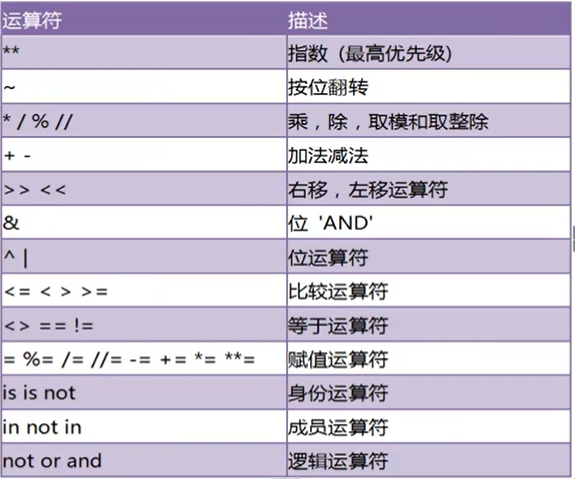
运算符优先级问题
复杂表达式一定要使用小括号组织
1.先乘除,后加减
2.位运算和算术运算>比较运算符>赋值运算符
可变字符串
在pyhton中,字符串不可变。可以使用io.StringIO对象或array模块原地修改字符串。
import io
s='hello,sxt'
sio=io.StringIO(s)
print(sio.getvalue())
sio.seek(7)
sio.write('g')
print(sio.getvalue())
字符串常用方法汇总
常用查找方法
len(a) 计算字符串长度
a.startswith('字符串') 是不是以指定字符串开头
a.endswith('字符串') 是不是以指定字符串结尾
a.find('字符串') 第一次出现指定字符串的位置
a.rfind('字符串') 最后一次出现指定字符串的位置
a.count('字符串') 指定字符串出现了几次
a.isalnum() 判断所有字符串全是字母或数字
a.isalpha() 判断所有字符串全是字母(含汉字)
去除首尾信息
strip() 去除首尾指定信息
lstrip() 去除首指定信息
rstrip() 去除尾指定信息
大小写转换
a.capitalize() 产生新的字符串,首字母大写
a.title() 产生新的字符串,每个单词都首字母大写
a.upper() 产生新的字符串,所有字符全转成大写
a.lower() 产生新的字符串,所有字符全转成小写
a.swapcase() 产生新的字符串,所有字母大小写转换
格式排版
a.center(10,'*') 居中
a.ljust(10,'*') 左对齐
a.rjust(10,'*') 右对齐
字符串驻留机制和字符串比较
字符串驻留:仅保存一份相同且不可变字符串的方法,不同值被存放在字符串驻留池中。(仅包含下划线、字母和数字会启用字符串驻留机制)
字符串比较和同一性
可以用==,!=进行字符串比较
使用is/ not is,判断两个对象是否同一个对象,比较的是对象的地址
成员操作符
in /not in 关键字,判断mou'g
按位或:表示取最大(每位)
按位与:最小
按位异:每位相同为0;相异为1
str()实现数字转型字符串
使用[]提取字符
正向搜索:最左侧第一个字符,偏移量(索引)是0,第二个偏移量1,以此类推,直到len(str)-1为止。
反向搜索:最右侧第一个字符,偏移量(索引)是-1,倒数第二个偏移量-2,以此类推,直到-len(str)为止。
a='abcd'
print(a[0])
print(a[-1])
replace()实现字符串替换
字符串不可变,创新了新字符串
a=a.replace("c","高")
转义字符
\(在行尾时) 续行符
\\ 反斜杠符号
\' 单引导
\" 双引导
\b 退格(Backspace)
\n 换行
\t 横向制表符
\r 回车
字符串拼接
1.用+拼接
2.多个字符串直接放到一起
字符串复制
用*实现字符串复制
不换行打印
前面调用print时,会自动打印一个换行符。
有时不想换行时,可以通过end="任意字符串"实现末尾添加任何内容。
print("sxt",end=' ')
print("sxt",end='\t')
从控制台读取字符串
input()
同一运算符
同一运算符用于比较两个对象的存储单元,实际比较的是对象的地址。
is 判断两个标识符是不是引用同一个对象
is not 判断两个标识符是不是引用不同对象
is与 == 区别:
is用于判断两个变量引用对象是否为同一个,既比较对象的地址
== 用于判断引用变量引用对象的值是否相等,默认调用对象的_eq_()方法
整数缓存问题
python仅对比较小的整数对象进行缓存,命令行中范围【-5,256】
Pycharm或保存为文件时,范围【-5,任何正整数】
is运算符比==效率高,在变量和None进行比较时,应该使用is