Max pooling 采样取各样区内最大
avg pooling 取平均


Max pooling 采样取各样区内最大
avg pooling 取平均
regression 找到函数输出
stride 步长
padding 填充0
layer 层
O' = O - learningrate*gradient
a.shape
ls
默认显示当前目录的文件
通配符
每一个命令,有10几个选项,10几个参数
文件以.开头的,相当于隐藏文件
/windows有分盘
而linux没有分盘。在直接用
除了home文件夹,其它的都不用动
只有第一个/才能称之为根目录
tree 的命令
Linux内核有几千万行代码
Linux发行版本
Android 是Linux kernel外面封装一圈java程序
桌面环境,是win的天下
操作系统,就是让多个程序一起执行
所谓的并发,莫过如此
Android的本质,就是linux
kernel是整个操作系统,最核以的东西
LINUX kernel 封装了java的东西,就是Android
Unix是整个OS的鼻祖
用同一门语言,运行在联想的电脑上,与华硕的电脑上,运行的结果不一样。
叫做跨硬件平台性比较差。
BCPL的第二个字母作为这种语言的名字,这就是C语言
C语言的主体完成,Thompson和Ritchie迫不及待地开始用它完全重写现在大名鼎鼎的Unix
迭代:已有版本,开发一个新的版本,称之为迭低
开源与闭源
他以小型UNIX(mini-UNIX)之意,将它称为MINIX
mini-Unix 用来教学
汽车导航:默认出厂的WIN CE
Android主要运行在移动端
win10 主要在PC上,个人电脑上
操作系统为自己控制硬件
什么是操作系统
操作系统OS
软件,能够直接控制硬件,向上支持应用软件使用
没有操作系统的
应用层软件,
【深度学习框架】
- Scikit-learn:面向机器学习,不支持 GPU 加速
- Caffe:第一个面向深度学习的框架
- Keras
- Theano
- Torch
- Singa
- PyTorch
- TensorFlow
- 线性回归需要标准化
决策树的分类依据之一
信息增益
【分类模型的评估标准】
【准确率】
estimator.score():一般最常见使用的是准确率,及预测结果正确的百分比
【混淆矩阵】
在分类任务下,预测结果和正确标记之间存在四种不同的组合,构成混淆矩阵(适用于多酚类)
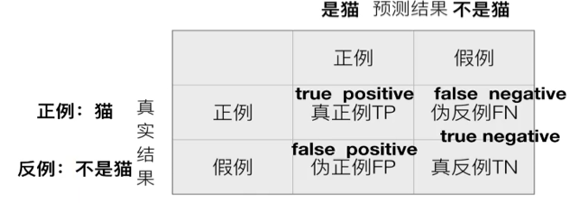 【精确率】
【精确率】
预测结果为正例的样本中,真实为正例的比例(查得准)

【召回率】
真实为正例的样本中,预测结果为正例的比例(查的全,对正样本的区分能力)
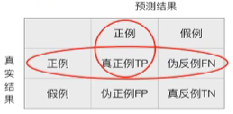
【分类模型评估API】
sklearn.metrics.classification_report (y_true, y_predict, target_names = None)
- y_true:真实目标值
- y_predict:估计器预测目标值
- target_names:目标类别名称
- return:每个类别精确率与召回率
朴素贝叶斯案例流程
1. 加载新闻数据,并进行分割
2. 生成文章特征词
3. 朴素贝叶斯流程进行预估