【深度学习框架】
- Scikit-learn:面向机器学习,不支持 GPU 加速
- Caffe:第一个面向深度学习的框架
- Keras
- Theano
- Torch
- Singa
- PyTorch
- TensorFlow


【深度学习框架】
- Scikit-learn:面向机器学习,不支持 GPU 加速
- Caffe:第一个面向深度学习的框架
- Keras
- Theano
- Torch
- Singa
- PyTorch
- TensorFlow
- 线性回归需要标准化
决策树的分类依据之一
信息增益
【分类模型的评估标准】
【准确率】
estimator.score():一般最常见使用的是准确率,及预测结果正确的百分比
【混淆矩阵】
在分类任务下,预测结果和正确标记之间存在四种不同的组合,构成混淆矩阵(适用于多酚类)
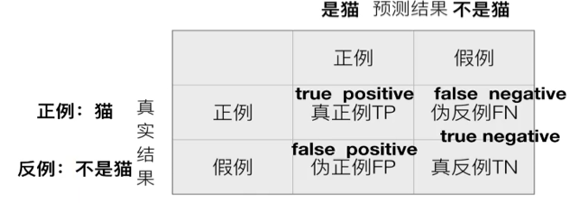 【精确率】
【精确率】
预测结果为正例的样本中,真实为正例的比例(查得准)

【召回率】
真实为正例的样本中,预测结果为正例的比例(查的全,对正样本的区分能力)
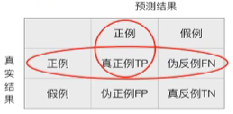
【分类模型评估API】
sklearn.metrics.classification_report (y_true, y_predict, target_names = None)
- y_true:真实目标值
- y_predict:估计器预测目标值
- target_names:目标类别名称
- return:每个类别精确率与召回率
朴素贝叶斯案例流程
1. 加载新闻数据,并进行分割
2. 生成文章特征词
3. 朴素贝叶斯流程进行预估
K近邻算法:相似的样本,特征之间的值应该都是相近的
k近邻算法:需要做标准化处理
【转换器】
fit_transform():输入数据并直接转换
fit():输入数据,但不做其他事
transform():进行数据的转换
【估计器】是一类实现了算法的API
1. 用于分类的估计器:
-- sklearn.neighbors
-- sklearn.naive_bayes
-- sklearn.linear_model.LogiscRegression
-- sklearn.tree
2. 用于回归的估计器
-- sklearn.linear_model.LinearRegression
-- sklearn.linear_model.Ridge
估计器流程
1、调用训练集:fit(x_train, y_train)
2、输入待预测的测试集数据:
2.1、y_predict = predict( x_test)
2.2、验证预测的准确率:score( x_test, y_test)
【sklearn 数据集】
- 数据集的划分:将数据集划分为训练集(建立模型)和测试集(评估模型)
- sklearn数据集划分API:sklearn.model_selection.train_test_split
--sklearn.datasets:加载获取流行数据集
1. datasets.load_*():获取小规模数据集,数据包含在datasets中
2. datasets.fetch_*(data_home=None):获取大规模数据集
--获取数据集返回的类型为datasets.base.Bunch(字典格式)
---data:特征数据数组,是 [n_samples*n_features] 的二维 numpy.ndarray 数组
---target:标签数组
---DESCR:数据描述
---feature_names:特征名
---target_names:标签名
-
-数据类型
1. 离散数据类型(计数数据):区间内不可分,整数,不能进一步提高精确度
2. 连续性数据:区间内可分,通常为非整数。变量可以在某个范围内任取数。
- 机器学习算法分类
1. 监督学习(预测):特征值+目标值
1.1 分类(目标值为离散型):k-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归、神经网络
1.2 回归(目标值为连续型):线性回归、岭回归
1.3 标注:隐马尔科夫模型
2. 非监督学习:特征值
2.1 聚类 k-means
- 特征抽取:将文本等原始数据转化为特征向量的形式
- 常用数据集数据的结构组成:特征值 + 目标值(有些数据集可以没有目标值)
- 样本:一组数据也可以称为一个样本。
- 数据中对于特征的处理:
1. pandas:工具。数据读取非常方便,可以处理数据的基本格式
2. sklearn:可以对特征进行处理——这类处理被称为特征工程。
# 机器学习不需要对样本进行去重
【特征工程】
- 特征工程是将原始数据转换为能更好地代表预测模型的潜在问题的特征的过程,从而提高对未知数据的预测准确性
- 安装scikit-learn
- 机器学习的数据:文件 csv
- 不用mysql的原因:
1. 具有性能瓶颈、读取速度慢
2. 格式不符合机器学习要求数据的格式
- pandas:读取数据的工具
- numpy(读取速度快)
- 可用数据集:Kaggle、UCI、scikit-learn
- 常用数据集数据的结构组成:特征值 + 目标值(有些数据集没有目标值)
- 什么是机器学习:数据中自动分析获得规律(模型),利用规律对未知数据进行预测
- 影响人工智能发展的重要因素:计算能力、数据大小、算法发展
- 使用场景:无人驾驶的场景识别、图片艺术化、医用彩超辨别、需求销量等数据预测
- 机器学习领域:自然语言处理、图像识别、传统预测
- 机器学习库和框架:scikit learn(机器学习)、tensorflow(深度学习)
- 书籍:统计学习方法、机器学习、python数据分析与挖掘实战、机器学习系统设计、面向机器智能tensorflow实践
- 课程概要:特征工程、模型策略优化、分类回归聚类、tensorflow、神经网络、图像识别、自然语言处理
python不适用的场景为效率性能要求较高的场景。c/go/java/c++都比他性能高。
最后一问结果是99.99999,是对的吗
numpy多用在大型、多维数组上执行数值运算;
for 遍历所有数值
print(输出便利数值)
for x in 数值
print()
海龟绘图我pycharm无法输出