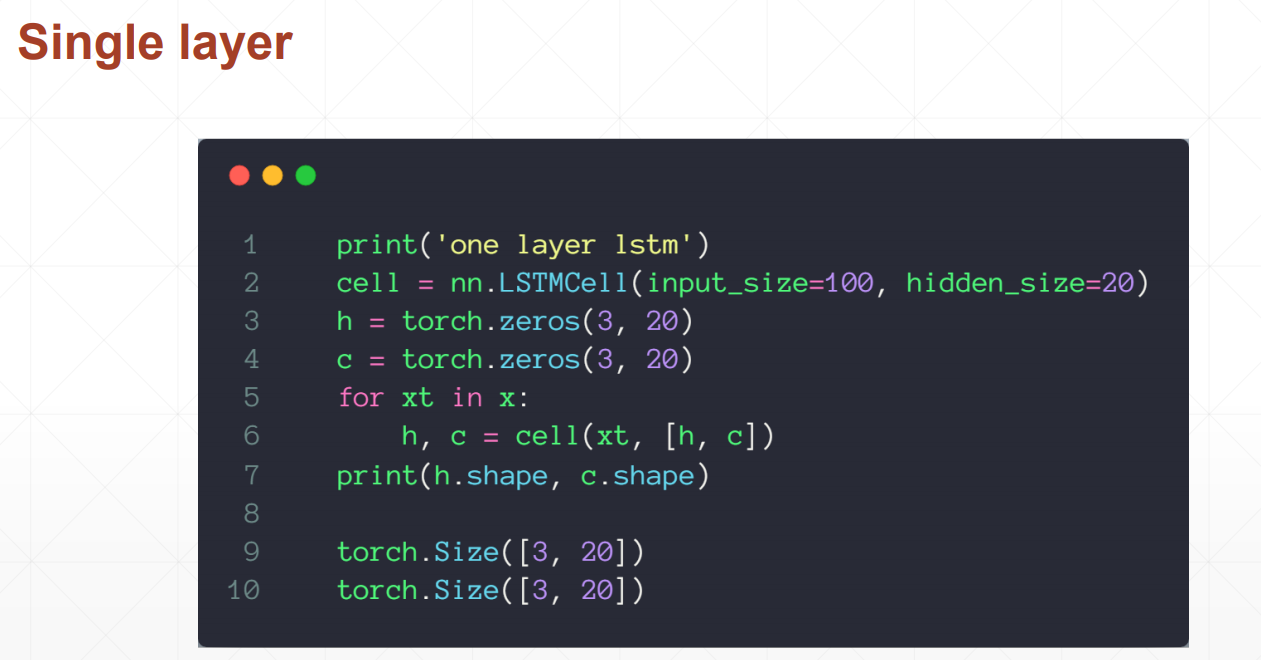
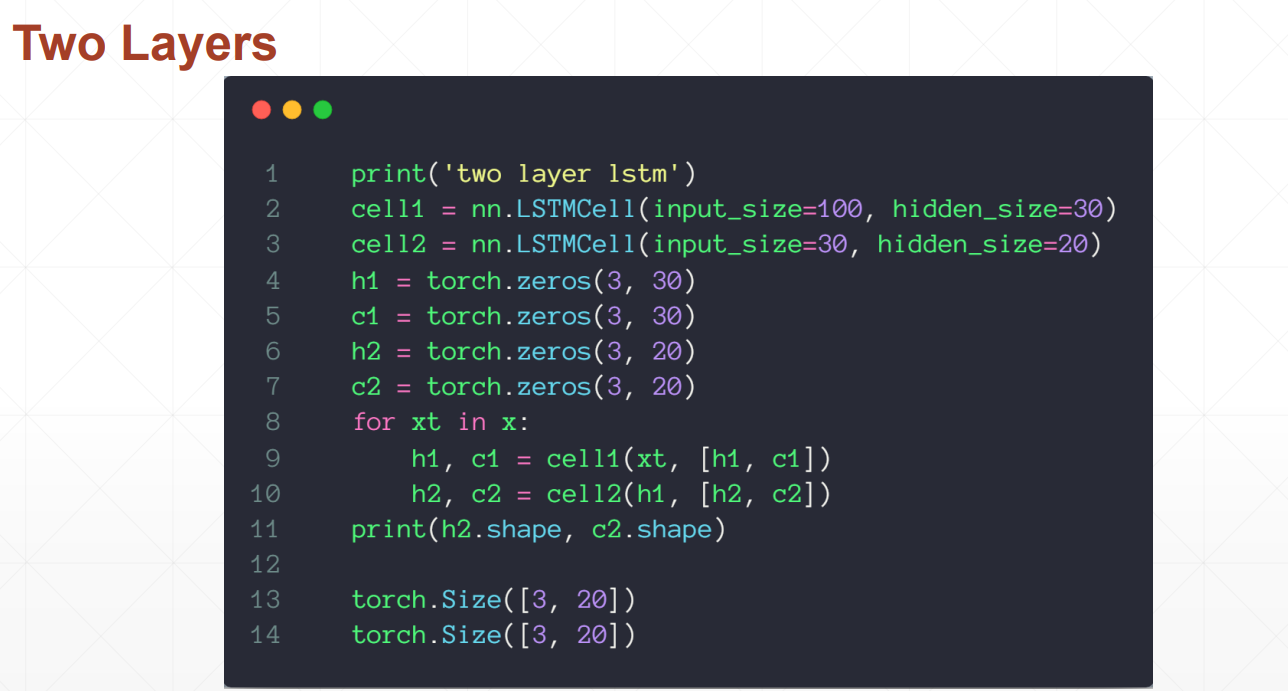
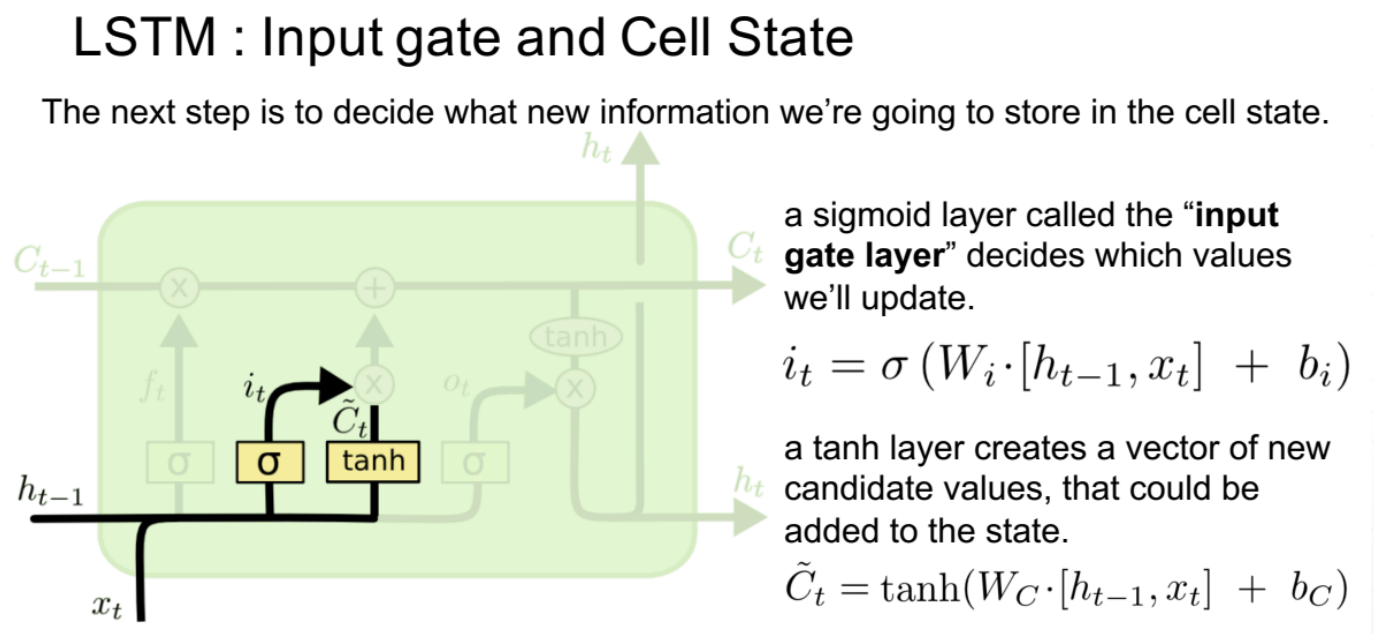
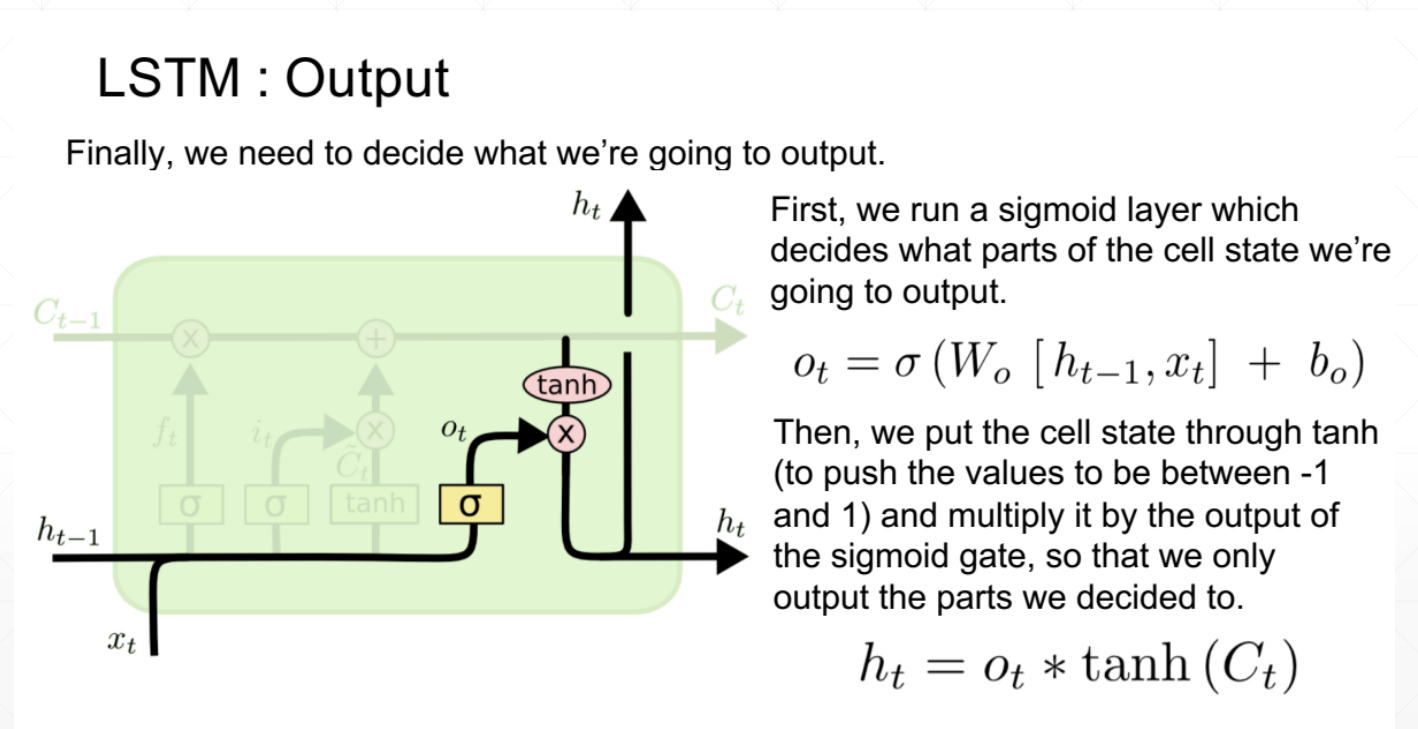
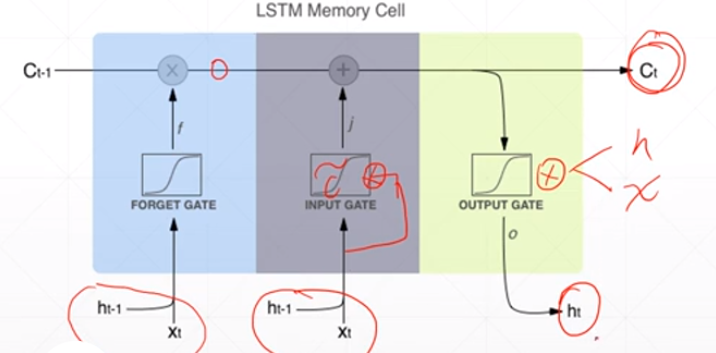
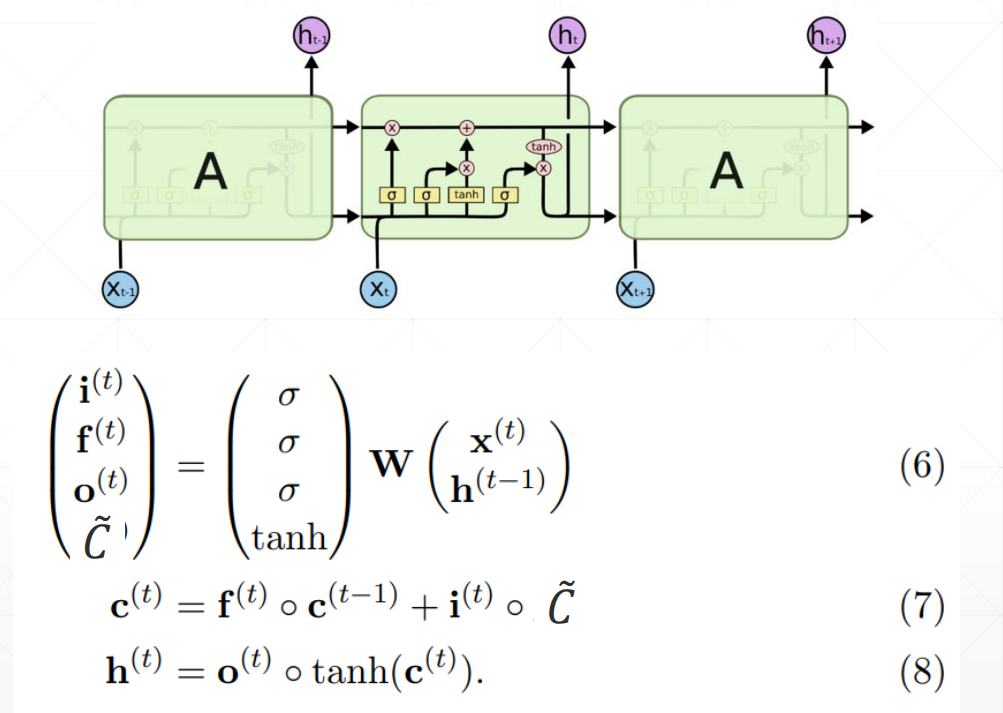
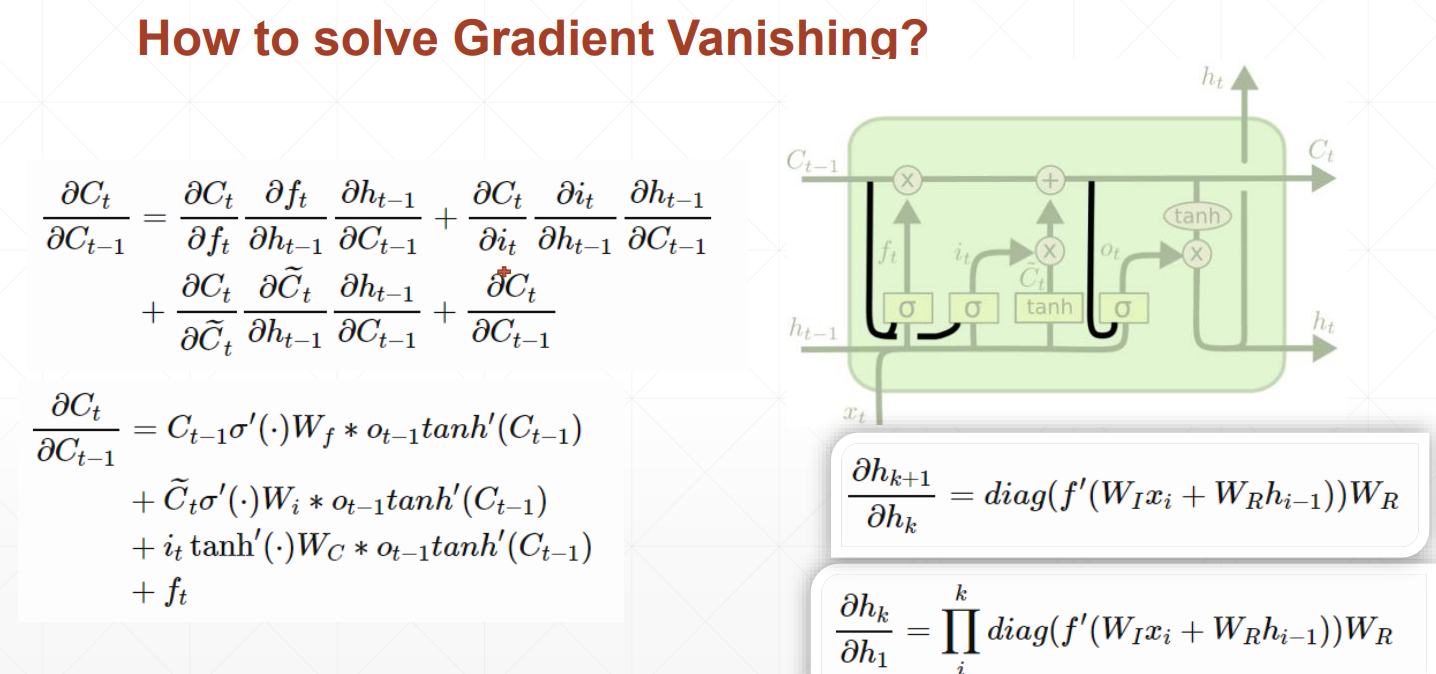
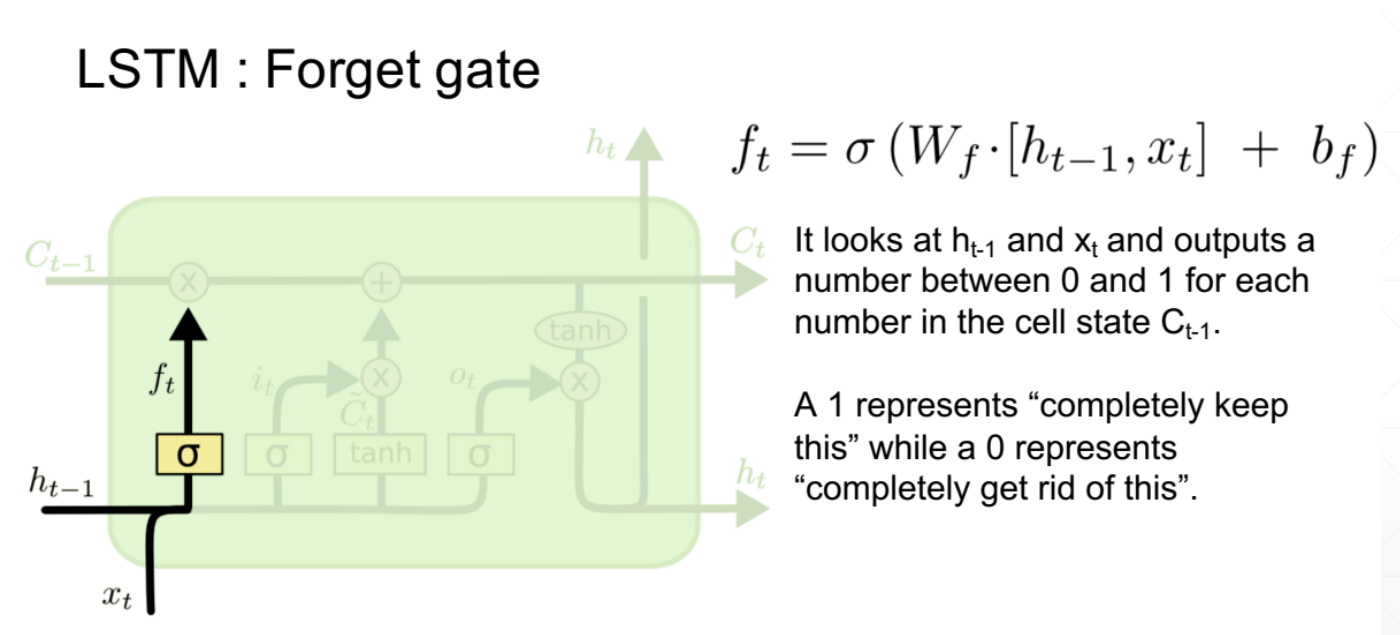
重要参数
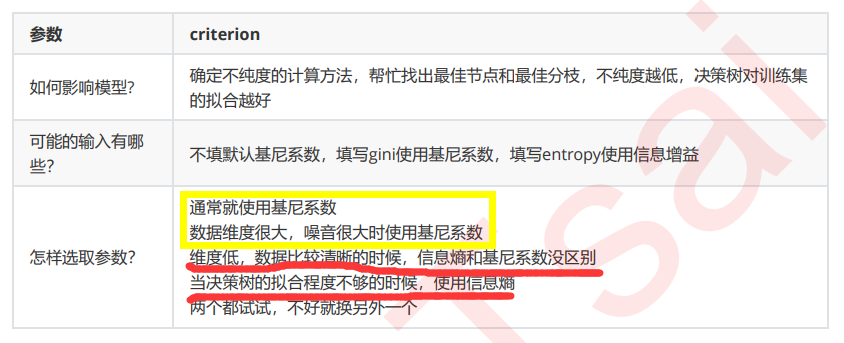
criterion
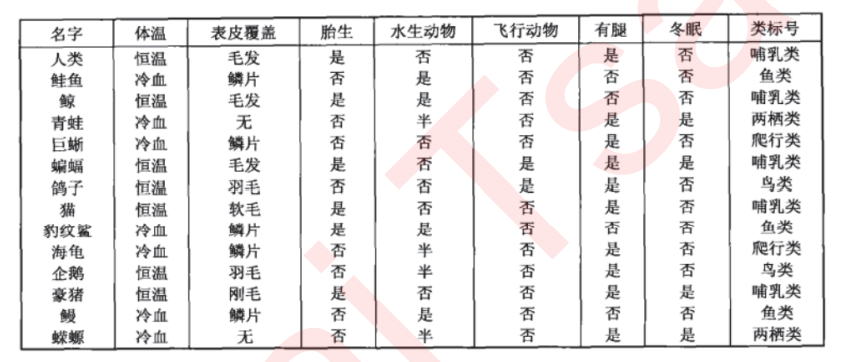
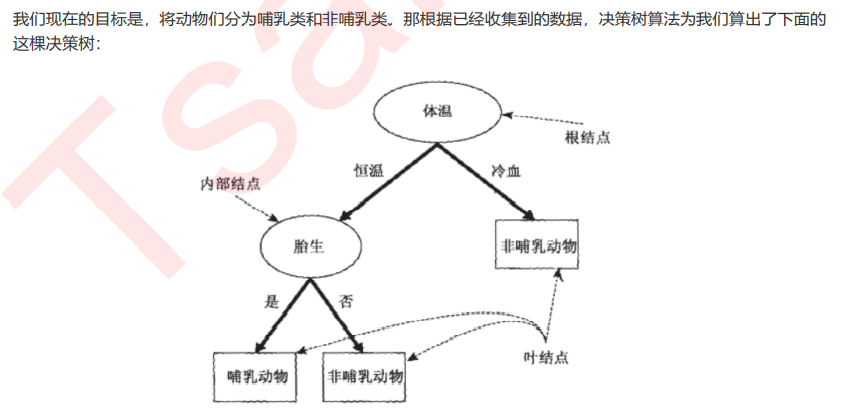
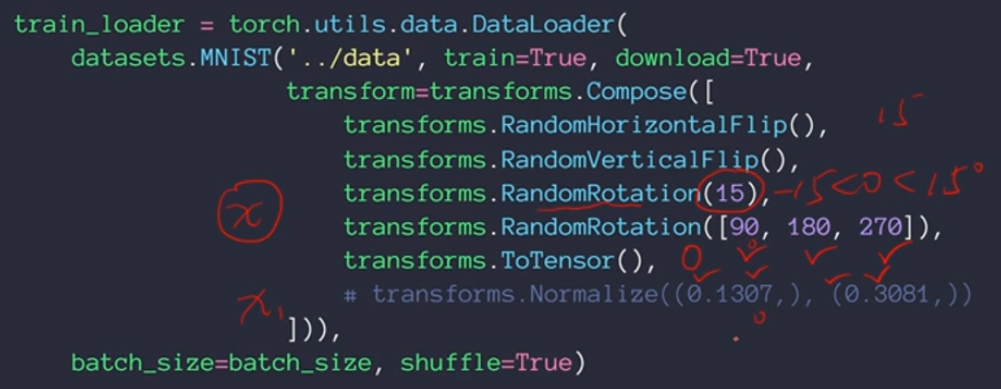
为了要将表格转化为一棵树,决策树需要找出最佳节点和最佳的分枝方法,对分类树来说,衡量这个“最佳”的指标 叫做“不纯度”。通常来说,不纯度越低,决策树对训练集的拟合越好。
不纯度基于节点来计算,树中的每个节点都会有一个不纯度,并且子节点的不纯度一定是低于父节点的,也就是 说,在同一棵决策树上,叶子节点的不纯度一定是最低的。
Criterion这个参数正是用来决定不纯度的计算方法的。sklearn提供了两种选择:
1)输入”entropy“,使用信息熵(Entropy) 2)输入”gini“,使用基尼系数(Gini Impurity)
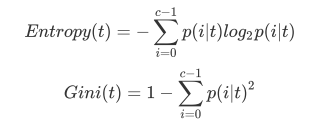

当使用信息熵 时,sklearn实际计算的是基于信息熵的信息增益(Information Gain),即父节点的信息熵和子节点的信息熵之差。
比起基尼系数,信息熵对不纯度更加敏感,对不纯度的惩罚最强。但是在实际使用中,信息熵和基尼系数的效果基 本相同。信息熵的计算比基尼系数缓慢一些,因为基尼系数的计算不涉及对数。另外,因为信息熵对不纯度更加敏 感,所以信息熵作为指标时,决策树的生长会更加“精细”,因此对于高维数据或者噪音很多的数据,信息熵很容易 过拟合,基尼系数在这种情况下效果往往比较好。当模型拟合程度不足的时候,即当模型在训练集和测试集上都表 现不太好的时候,使用信息熵。当然,这些不是绝对的