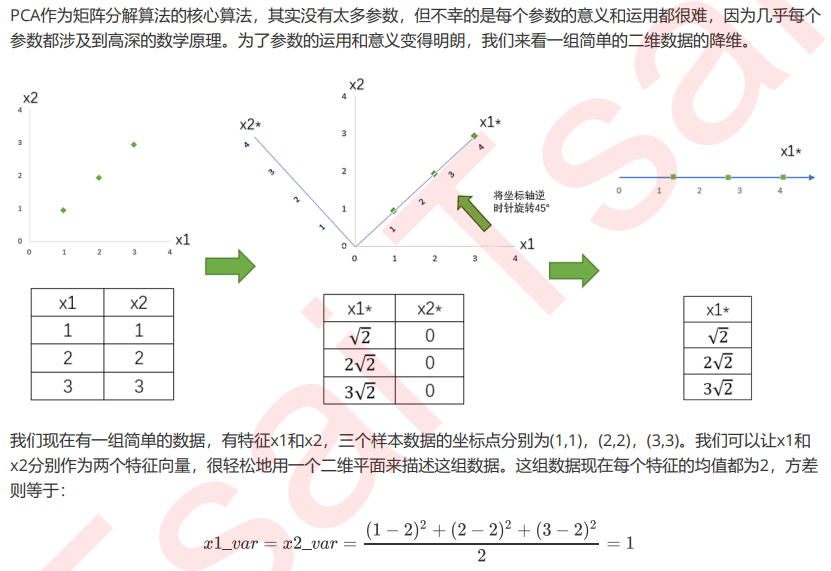
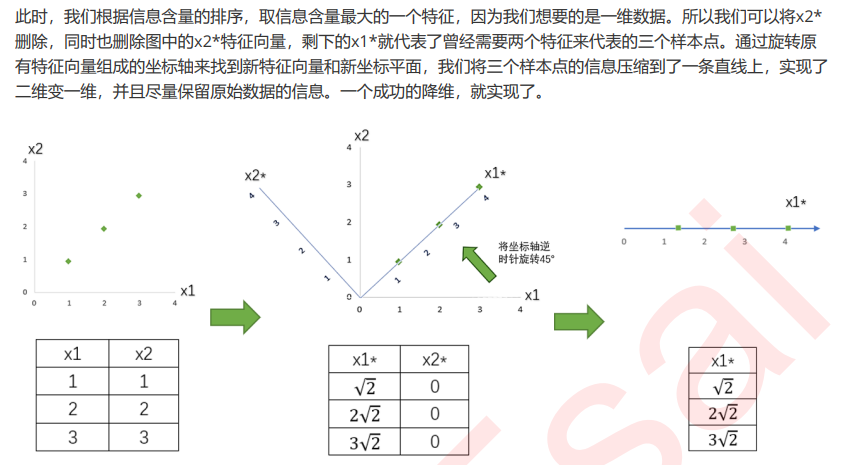
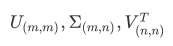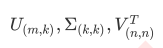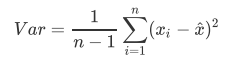特征选择:方差过滤
```python
from sklearn.feature_selection import VarianceThreshold #特征选择,根据方差进行过滤
def var():
'''
特征选择-选择低方差的特征
:return:None
'''
var=VarianceThreshold(threshold=1.0)#保留方差值为1的数值
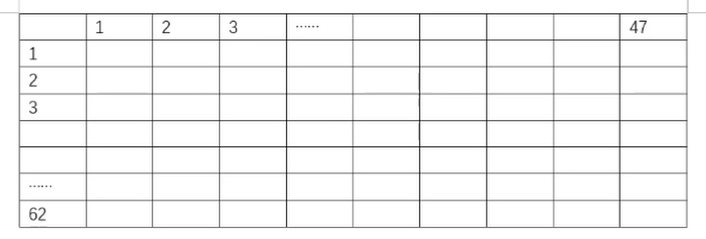
data=var.fit_transform([[0,2,0,3],[0,1,4,3],[0,1,1,3]])#三行四列的二维数组
print(data)
return None
if __name__=='__main__': #调用
var()
```
PCA:主成分分析
把维度降低,但是数据信息尽可能不损耗