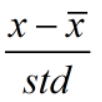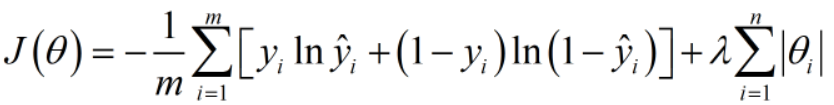数据增强
神经网络对数据的要求非常饥渴,需要贴有标签的大量数据
当数据量有限的时候:1、要减少神经网络的隐藏层;2、Regularization,迫使一部分权值接近于0,让网络的表现更加稳定;3、数据增强,目前的数据量较少,想办法对数据进行变换——旋转、裁剪加噪声等
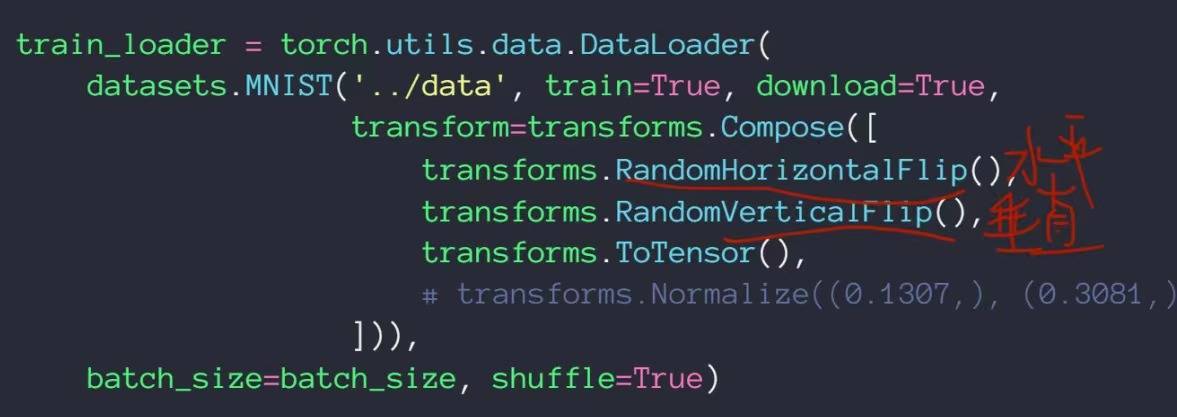
Flip——翻转
可以从水平方向和竖直方向进行翻转,这里增加了random属性,代表翻转是具有随机性的,有可能进行水平翻转,也有可能不翻转,有可能垂直翻转,也有可能不翻转
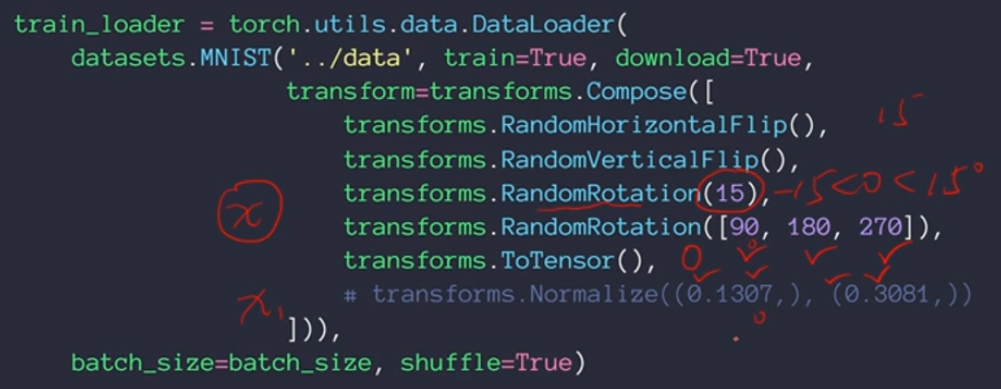
Rotate——旋转
Scale——缩放
以中心点为标准进行缩放Resize,传入的是list

Crop Part
随机得进行裁剪
transform是torchvision里面自带的包, transform.Compose()可以把一系列翻转、旋转、裁剪和缩放操作组合在一起

Noise——加噪声,用的不多
即使得到了无穷多的数据,由于进行变换后的数据和原本的数据非常接近,所以训练的结果仅仅能得到一个很小的提升


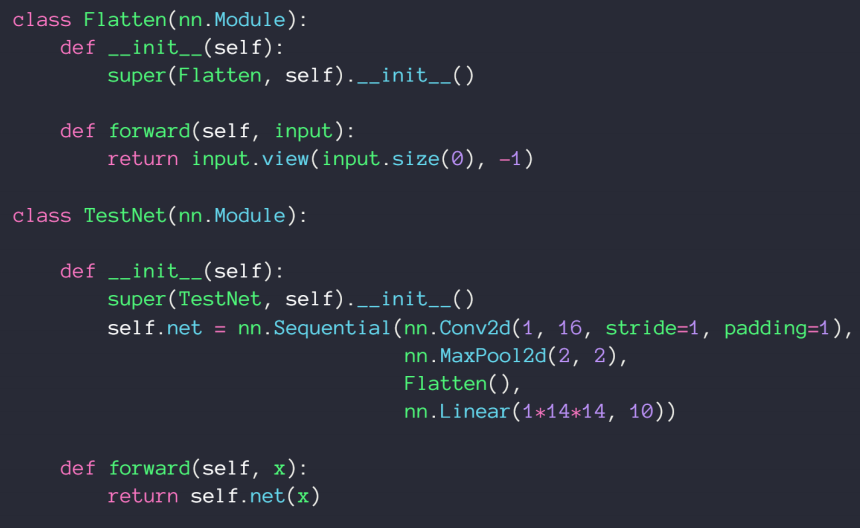







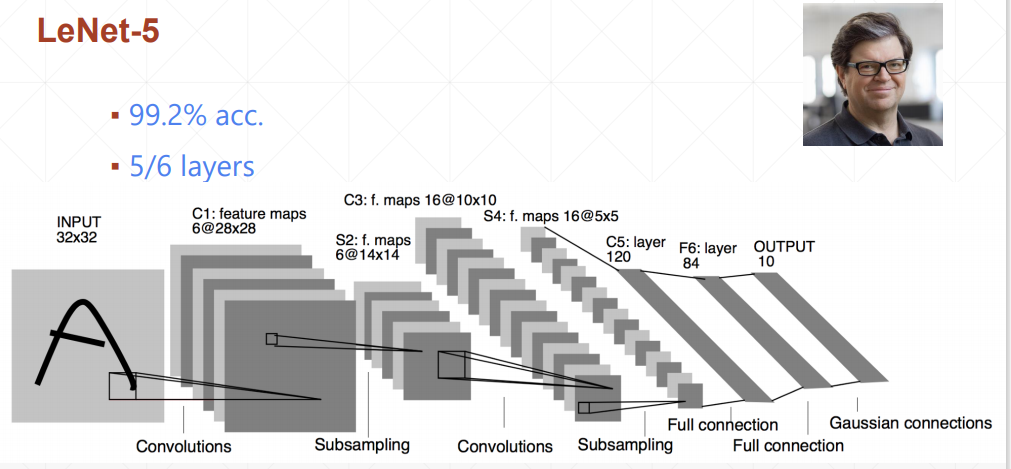
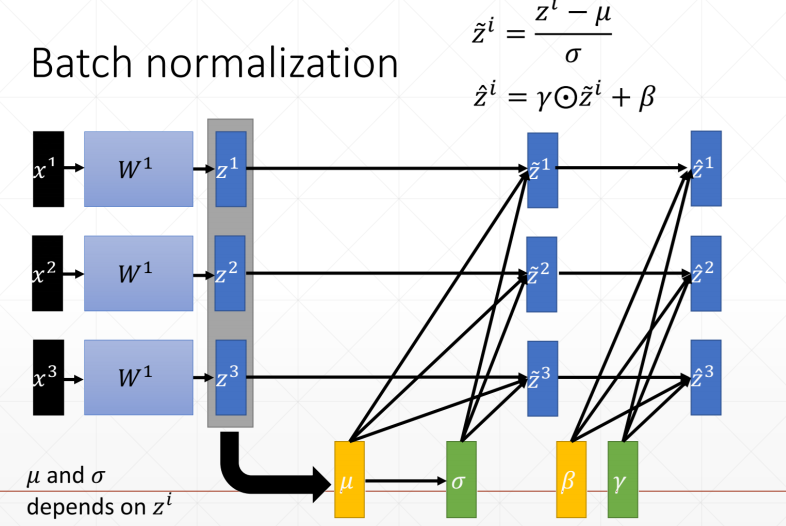
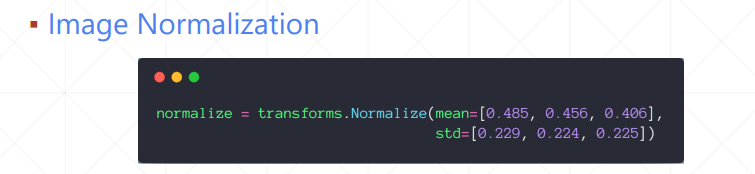
 我们主要学习Batch normalization以通道为基准,计算每个通道上的均值和方差,然后通过减均值除以方法来使这些值均匀得分布在某个范围内
我们主要学习Batch normalization以通道为基准,计算每个通道上的均值和方差,然后通过减均值除以方法来使这些值均匀得分布在某个范围内