生成器推导式,产生生成器对象
s=(x*2 for x in range(5))
tuple(s) 转换为元组,用完一次s失效
s._next_()指针调动,输出当前值并下移

 已关闭
已关闭
生成器推导式,产生生成器对象
s=(x*2 for x in range(5))
tuple(s) 转换为元组,用完一次s失效
s._next_()指针调动,输出当前值并下移
list.index(值,位置1,位置2)返回位置1-到位置2之间的第一个“值”的位置。
list.count(值)
成员资格
值 in (not in) list,返回True,False
元组是不可变序列
创建元组
a=(,,,)
a=tuple(字符,数字,列表)
多维列表:列表嵌套
a[一维引索][二维引索]
列表排序 修改原列表,不建立新列表
list.sort()默认升序排列
list.sort(reverse=True)降序排列
import random
random.shuffle(list)
列表排序,建立新列表
new_list=sorted(list),升序
new_list=sorted(list,reverse=True),降序
c=reversed(list)返回逆序排列的迭代器对象,只能用一次
max(list), min(list)
sum(list),数值型列表可用
列表元素提取
list[起始位置:终点位置:step], 从起始位置到终点-1位置,step为-1时反向提取
列表元素删除
del a[位置],有数组拷贝,地址不变
list.pop(位置),删除位置上的元素并返回元素值
list.remove(值),删除第一个指定值,不存在就报错。
列表增加,删除
append(),
尽量减少在列表中间修改,涉及大量复制会消耗内存,尽量在尾部删,增。
a=a+[],非尾部添加,实际是创建新列表,耗内存
expend(),
原地址尾部添加
expend([50,60]),不改变地址,适合两个列表对接
insert(索引,值) 元素插入指定位置,设计大量拷贝,地址不变
列表乘法 a=a*3
pandas时间序列
现在我们有2015到2017年25万条911的紧急电话的数据,请统计出出这些数据中不同类型的紧急情况的次数,如果我们还想统计出不同月份不同类型紧急电话的次数的变化情况,应该怎么做呢?
为什么要学习pandas的时间序列
不管在什么行业,时间序列都是一种非常重要的数据形式,很多统计数据以及数据的规律也都和时间序列有着非常重要的联系
时间格式化
python中时间日期格式化符号:
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
pandas数据重采样
指的是将时间序列从一个频率转化为另一个另一个频率进行处理的过程,将高频率数据转化为低频率为降采样,低频率转化为高频率为升采样
关于索引和复合索引
merge——进行列合并,合并的是相同索引值得列默认的方式是inner,取交集,当没有相同的数的时候取空
思考:对于一组电影数据,如果要对这些数据进行分类,应该如何操作?
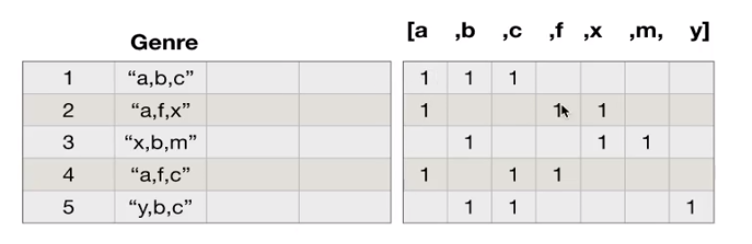
首先,先构一个二维数组,行数等于gener_list的数据量,即取出来genre这一列的数据,通过逗号进行分割,即将每一行数据分割出来一二维数据的形式返回列表中
df["Genre"].str.split(",").tolist()
然后将这个list里面的数据都转换为一维数组且去重
再构建一个新的二维数组,最初的值都为零,行是genre 的数据量,列表是一维数组的数据量,分类最为列索引
字符串的方法

pandas里面计算mean()时,可以直接跳过nan,来返回其他值得平均数
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
pandas的索引
DataFrame的基本属性
为什么要学习pandas?
numpy处理数值型数据;pandas用来处理字符串和时间序列等
pandas的常用数据类型
(1)series——一维、带标签的数组
(2)DataFrame——二维数组

生成随机数的方法