随机森林的回归。
分类树与回归树,MSE均方误差。
回归树衡量指标mse、firedman_mse与MAE
sklearn使用负值的均方误差作为衡量指标,因为表示的是损失。
load_boston是一个标签连续型数据集。
regressor是模型
boston.data完整的矩阵、boston.target是标签。来回验证十次,scoring选择指标进行打分。

 已关闭
已关闭
随机森林的回归。
分类树与回归树,MSE均方误差。
回归树衡量指标mse、firedman_mse与MAE
sklearn使用负值的均方误差作为衡量指标,因为表示的是损失。
load_boston是一个标签连续型数据集。
regressor是模型
boston.data完整的矩阵、boston.target是标签。来回验证十次,scoring选择指标进行打分。
一半以上的决策树判断错误,才会导致随机森林才会判断错误。
comb是求和。
相同的训练集与参数,随机森林中的树会有不同的判断结果,选择重要的特征进行提问。
estimators,查看森林中树的参数或属性。每棵树中的random_state不一样,导致每棵树都不一样。
random_state固定,随机森林中的树是固定的,但随机挑选的特征,导致树是不一样。随机性越大,效果越好。
bootstrap用于控制抽样技术的参数。
自主集:从原始训练集中进行n次有放回抽样,得到的数据集。自主集会包含63%的原始数据集元素。剩下37%数据可以作为测试模型的数据,称为袋外数据。
wine.target为wine的标签。
一个自助集里,样本A永远不被抽到的概率:(1-1/n)^n
oob_score训练分数。
apply返回所在叶子节点的索引
predict_proba返回每个样本对应类别的标签的概率。
n_estimators基评估器数量,该值越大,越好。
到达一定程度后,精确性会开始波动。
集成算法:在数据上构建多个模型,集成所有模型的建模结果。
集成算法会考虑多个评估器的建模结果,汇总之后得到一个综合的结果。
集成评估器:基评估器,装袋法,提升法,stacking
sklearn中的ensemble,集成算法有一半以上都是树的模型。决策树用于分类和回归问题。通过有特征和标签的表格中,通过对特定特征进行提问,总结出决策规则。
如何找到正确的特征去提问,定义衡量分支质量的指标不纯度。
.开头是隐藏文件l
排序算法的稳定性:将原有相等键值的记录维持相对次序。
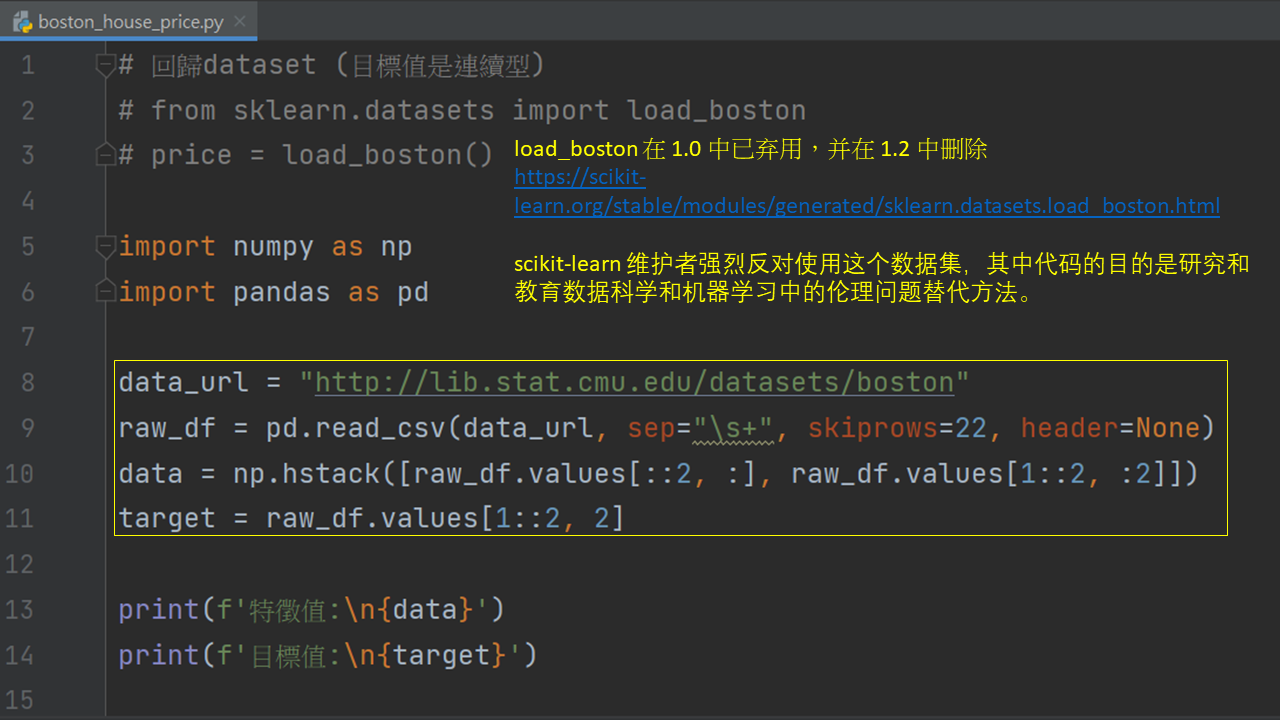
load_boston 在 1.0 中已弃用,并在 1.2 中删除
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_boston.html
scikit-learn 维护者强烈反对使用这个数据集,其中代码的目的是研究和教育数据科学和机器学习中的伦理问题替代方法。
Imputer, 已更新很久了
课程是旧版本, 我为新版本稍作说明

as a reminder for classmates, currently we use 'sklearn' rather than 'scikit-learn' in coding ;)
機器學習推薦書:
1. 機器學習 (西瓜書)
2. Python數據分析與挖掘實戰
3. 機器學習系統設計
4. 面向機器智能TensorFlow實戰
5. TensorFlow技術解析與實戰
少用加号
数据组织方式
一组数据如何保存 数据结构
抽象数据类型:确定数据组织形式,数据上的一组操作,只有相应的接口。
不会进行函数调用的步骤才叫做基本步骤。
算法时间复杂度:描述算法时间的多少
如何修改
机器学习简介
机器学习、深度学习可以做什么?
(自然语言处理、图象识别、传统预测)
机器学习库和框架
scikit learn、TensorFlow
课程定位:
以算法、案例为驱动的学习,浅显易懂的数学知识
注意:参考书比较晦涩难懂,不建议直接读
课程目标:
熟悉机器学习各类算法的原理
掌握算法的使用,能够结合场景解决实际问题
掌握使用机器学习算法库和框架
机器学习课程
特征工程;模型、策略、优化,分类、回归和聚类,TensorFlow,神经网络,图象识别,自然语言处理
sklearn中的信息熵,实际上是信息增益。即父节点的信息熵-子节点的信息熵。
非参数:即不限制数据结构和类型
有监督:有标签
from pyplot as plt 重命名,简化
temperature是气温, 100度很吓人啦 XD
