列表排序
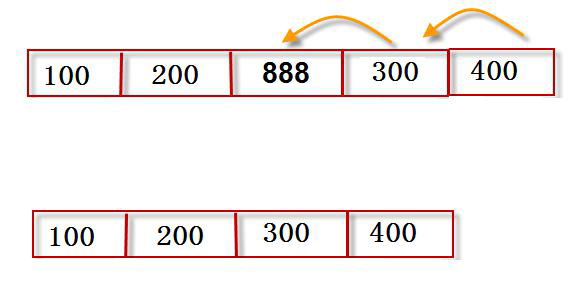
1.修改原列表,不建新列表的排序
>>> a = [20,10,30,40]
>>> a.sort() #默认是升序排列
>>> a
[10, 20, 30, 40]
>>> a = [10,20,30,40]
>>> a.sort(reverse=True) #降序排列
>>> a
[40, 30, 20, 10]
>>> import random
>>> random.shuffle(a) #打乱顺序
>>> a
[20, 40, 30, 10]
2.建新列表的排序
我们也可以通过内置函数sorted()进行排序,这个方法返回新列表,不对原列表做修改。
>>> a = [20,10,30,40]
>>> id(a)
46016008
>>> a = sorted(a) #默认升序
>>> a
[10, 20, 30, 40]
>>> id(a)
45907848
>>> c = sorted(a,reverse=True) #降序
>>> c
[40, 30, 20, 10]
3.reversed()返回迭代器
内置函数reversed()也支持进行逆序排列,与列表对象reverse()方法不同的是,内置函数
reversed()不对原列表做任何修改,只是返回一个逆序排列的迭代器对象。(也可用切片,设置步长-1)
>>> a = [20,10,30,40]
>>> c = reversed(a)
>>> c
<list_reverseiterator object at 0x0000000002BCCEB8>
>>> list(c)
[40, 30, 10, 20]
>>> list(c)
[]
list_reverseiterator。也就是一个迭代对象。同时,我们使用list(c)进行输出,发现只能使用一次。第一次输出了元素,第二次为空。那是因为迭代对象在第一次时已经遍历结束了,第二次不能再使用。
列表相关的其他内置函数汇总
max 和min 返回列表中最大和最小值。
sum 对数值型列表的所有元素进行求和操作,对非数值型列表运算则会报错。