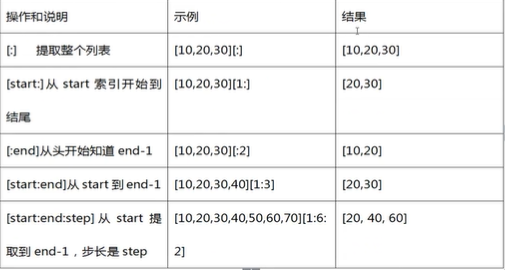
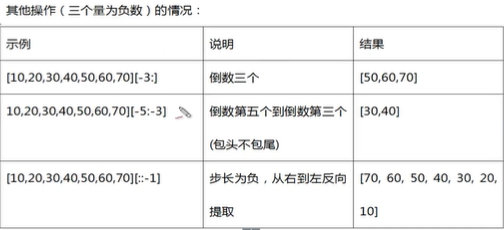
字典元素添加、修改、删除
1.给字典新增'键值对'。如果'键'已经存在,则覆盖旧得键。如果键不存在,则新增'键值对'。
a={'name':'lynn','age':18,'job':'planner'}
a['add']='南京路1号'
a['age']=16
print(a)
2.使用update()将新字典中所有键值对全部添加到旧字典对象上。如果key有重复,直接覆盖。
a={'name':'lynn','age':18,'job':'planner'}
b={'name':'ben','age':120,'sex':'man'}
a.update(b)
print(a)
3.字典中元素的删除,可以用del()或者clear()全删;pop()删除指定键值对,并返回对应的'值对象'。
b=a.pop('age')
4.popitem()随机删除和返回该键值对
a.popitem()