numpy的索引和切片
索引从0开始
2:取得连续多行,[[2,5,6]]多一个[]取得不连续的行
:,1取得单列
:,1:取得连续列
:,[]取得不连续列
取得行列交叉的内容
取得不相邻的点


numpy的索引和切片
索引从0开始
2:取得连续多行,[[2,5,6]]多一个[]取得不连续的行
:,1取得单列
:,1:取得连续列
:,[]取得不连续列
取得行列交叉的内容
取得不相邻的点
异常类型: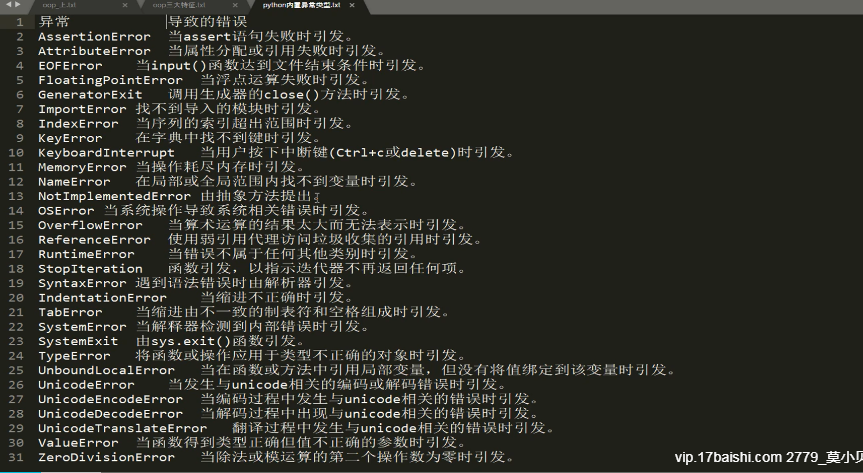
mysql数据查询
条件查询:
比较条件: > < = != <> 跟在where后面
in 查询 指定一个数据容器
between 表示一个区间 1到10 还可以表示时间范围
null值的判断 如果是一个空值对象的话 用is判断
如果是空字符串的话,则使用 = 判断
排序 order by 【asc升序 desc降序】可以指定多个字段排序;
聚合函数:
count()
max()
min()
length()
sum()
avg()
round()
date()
substr() left right
分组和分页
分组 group by
as 取别名
分组条件的筛选 where having
where 跟在from后面
having跟在group by后面
limit分页 select * from student limit start(起始位置) count(读取数量)
连接查询
内连接:inner join 两种表共同的数据
左连接:left join 参考左边的表为基准查询表,右边的表用null填充;
右连接 right join 参考右边的表为基准查询表,左边的表用null填充
子查询
1、标量查询 一行一列查询 单个值
2、列级子查询 一行多列 多个值
3、行级子查询 多行一列
4、表级子查询 多行多列【用来做数据源】
保存查询结果:
insert into 表名 select 查询来充当数据源;
union去重输出
union all 输出多次查询的结果;
这个老师的逻辑能力和语言组织能力真的是匮乏 前言不搭后语 自己把自己绕进去了
讲的真垃圾
这课程讲的就和拿着稿子照本宣科一样
如果要计算某个维度下的用户数,不要直接count()
排序:
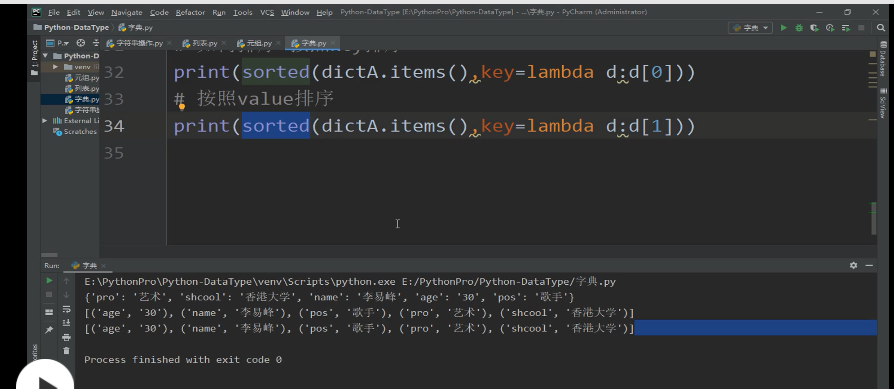
字符串及常用方法:

等腰三角形:
a=' name '
b=a.strip()去除空格
lstrip()删除左边的空格
rstrip()删除右边的空格
capitalize()首字母变大写
id()内存地址
常用格式化符号: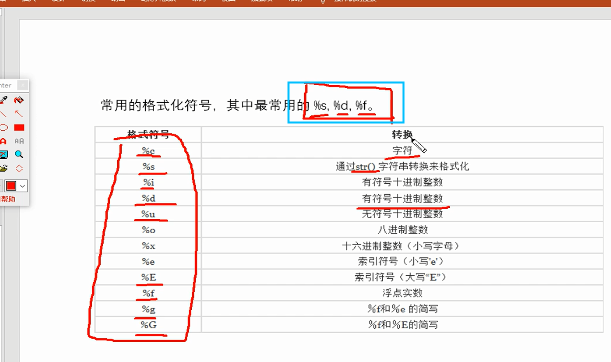
 python数据类型
python数据类型
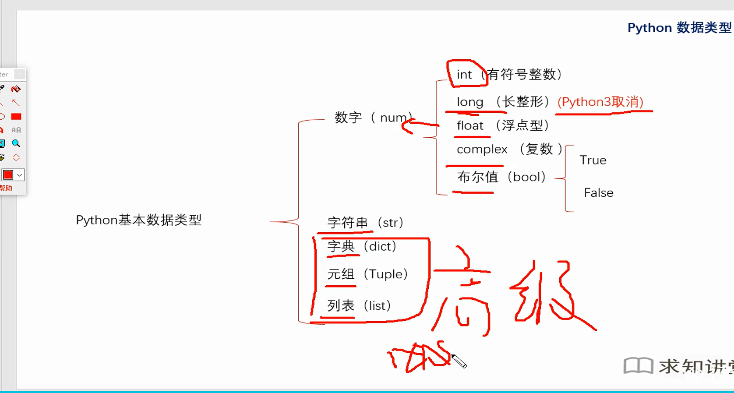
查数据类型:用type查询
a=10
print(type(a))
单行注释:#
多行注释:‘’‘’‘’或者'''
如: ‘’‘’‘’
注释为。。。。。。。
‘’‘’‘’
或者
'''
注释。。。。。。。
'''
比较运算是布尔类型的数据(ture,false)
如何定义变量和使用:
a=10 int(整数类型)
a=‘吴老师’str(字符串类型)
a=12.67 float(浮点类型)
a=True bool (布尔值)
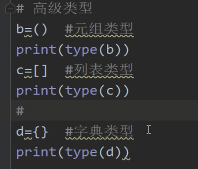
b=()tuple(元组类型)
c=【】list(列表类型)
d={}dict (字典类型)
变量的命名不能以数字来开头
变量区分大小写
关键字不能定义
如何定义变量和使用:
a=10 int(整数类型)
a=‘吴老师’str(字符串类型)
a=12.67 float(浮点类型)
a=True bool (布尔值)
全列插入:
insert into 表名 values( ‘数据1’, ‘数据2’, ‘数据3’……)
部分插入:
insert into 表名 (字段1,字段2 ……)values( ‘数据1’, ‘数据2’, ……),( ‘数据1’, ‘数据2’, ……)
prog:文件名
usage:用途描述
description:文件描述
epilog