最大熵模型:


最大熵模型:
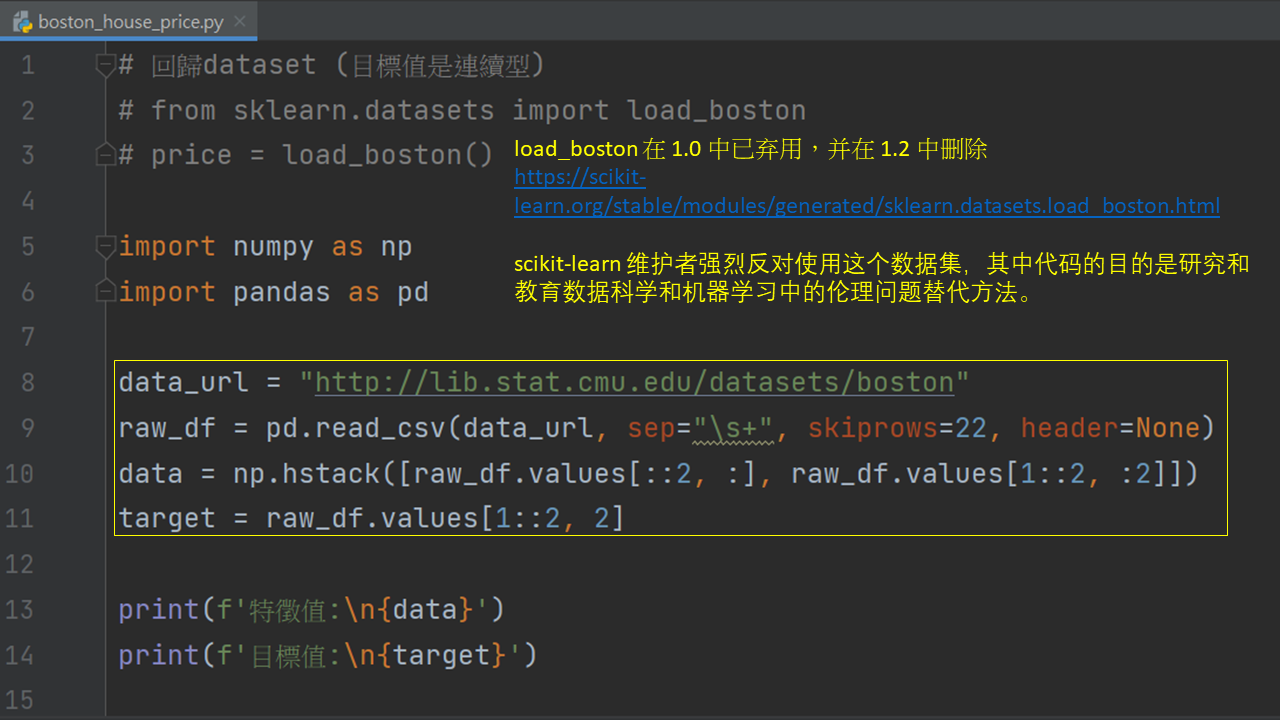
load_boston 在 1.0 中已弃用,并在 1.2 中删除
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_boston.html
scikit-learn 维护者强烈反对使用这个数据集,其中代码的目的是研究和教育数据科学和机器学习中的伦理问题替代方法。
#apply返回每个测试样本所在叶子节点的索引
clf.apply(xtext)
#predict返回每个测试样本的分类、回归结果
clf.predict(xtest)
#决策树 # from sklearn import tree#导入需要的模块 # clf=tree.DecisionTreeClassifier()#实例化 # clf=clf.fit(x_train,y_train)#用训练集数据训练模型 # result=clf.score(x_test,y_test)#导入测试集,从接口中调用需要的信息进行打分
citerion:不纯度,不纯的越低,训练集拟合越好
机器学习
Imputer, 已更新很久了
课程是旧版本, 我为新版本稍作说明

as a reminder for classmates, currently we use 'sklearn' rather than 'scikit-learn' in coding ;)
機器學習推薦書:
1. 機器學習 (西瓜書)
2. Python數據分析與挖掘實戰
3. 機器學習系統設計
4. 面向機器智能TensorFlow實戰
5. TensorFlow技術解析與實戰
机器学习简介
机器学习、深度学习可以做什么?
(自然语言处理、图象识别、传统预测)
机器学习库和框架
scikit learn、TensorFlow
课程定位:
以算法、案例为驱动的学习,浅显易懂的数学知识
注意:参考书比较晦涩难懂,不建议直接读
课程目标:
熟悉机器学习各类算法的原理
掌握算法的使用,能够结合场景解决实际问题
掌握使用机器学习算法库和框架
机器学习课程
特征工程;模型、策略、优化,分类、回归和聚类,TensorFlow,神经网络,图象识别,自然语言处理
步长定义
good 重点内容
秩 铺垫
要点总结
二阶导数是凸函数?
SymPy 符号运算包 函数运算
1.O表示多项式的阶
2.o (n)
上确界:M=supE
下确界:M=infE
向量组的秩
所有等价线性无关组含有的向量个数相等
支持向量机的分类方法,是在这组分布中找出一个超平面作为决策边界,使模型在数据上的 分类误差尽量接近于小,尤其是在未知数据集上的分类误差(泛化误差)尽量小。

决策边界一侧的所有点在分类为属于一个类,而另一侧的所有点分类属于另一个类。如果我们能够找出决策边界, 分类问题就可以变成探讨每个样本对于决策边界而言的相对位置。比如上面的数据分布,我们很容易就可以在方块 和圆的中间画出一条线,并让所有落在直线左边的样本被分类为方块,在直线右边的样本被分类为圆。如果把数据 当作我们的训练集,只要直线的一边只有一种类型的数据,就没有分类错误,我们的训练误差就会为0。
但是,对于一个数据集来说,让训练误差为0的决策边界可以有无数条。