变量的删除操作:
a=3
del a
此时a就被删除了。


变量的删除操作:
a=3
del a
此时a就被删除了。
mysql数据查询
条件查询:
比较条件: > < = != <> 跟在where后面
in 查询 指定一个数据容器
between 表示一个区间 1到10 还可以表示时间范围
null值的判断 如果是一个空值对象的话 用is判断
如果是空字符串的话,则使用 = 判断
排序 order by 【asc升序 desc降序】可以指定多个字段排序;
聚合函数:
count()
max()
min()
length()
sum()
avg()
round()
date()
substr() left right
分组和分页
分组 group by
as 取别名
分组条件的筛选 where having
where 跟在from后面
having跟在group by后面
limit分页 select * from student limit start(起始位置) count(读取数量)
连接查询
内连接:inner join 两种表共同的数据
左连接:left join 参考左边的表为基准查询表,右边的表用null填充;
右连接 right join 参考右边的表为基准查询表,左边的表用null填充
子查询
1、标量查询 一行一列查询 单个值
2、列级子查询 一行多列 多个值
3、行级子查询 多行一列
4、表级子查询 多行多列【用来做数据源】
保存查询结果:
insert into 表名 select 查询来充当数据源;
union去重输出
union all 输出多次查询的结果;
一· 认识python
1.特点:
可读性强
简洁
面向对象
免费和开源
可移植和跨平台
2.
最大熵模型:
排序算法的稳定性:将原有相等键值的记录维持相对次序。
二维列表
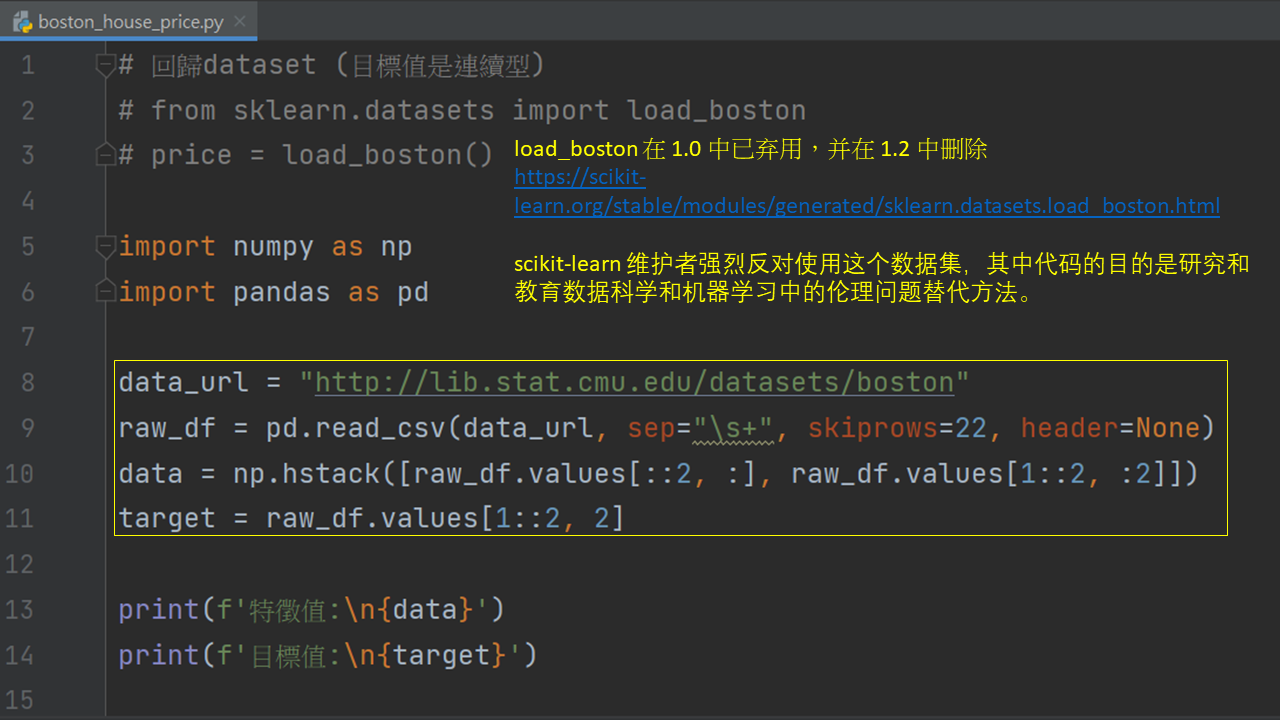
load_boston 在 1.0 中已弃用,并在 1.2 中删除
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_boston.html
scikit-learn 维护者强烈反对使用这个数据集,其中代码的目的是研究和教育数据科学和机器学习中的伦理问题替代方法。
特征函数与中心极限定理没看懂
Imputer, 已更新很久了
课程是旧版本, 我为新版本稍作说明

贝叶斯学派
逆概率
pxy = px * py 独立
若不独立
条件概率
P(x|y) = P(xy) /P(y)
as a reminder for classmates, currently we use 'sklearn' rather than 'scikit-learn' in coding ;)
python 的语言简洁
有c语言编写
機器學習推薦書:
1. 機器學習 (西瓜書)
2. Python數據分析與挖掘實戰
3. 機器學習系統設計
4. 面向機器智能TensorFlow實戰
5. TensorFlow技術解析與實戰
split()分割
不指定分隔符默认空白字符分割
例如
a = ‘to be or not to be’
split(a)
join()合并
例如
a = ['a','b','c']
''.join(a)
同一运算符
实际比较的是对象的地址
is 与 == 的区别:
is是比较两个变量引用的对象是否为同一个
==是比较引用变量引用对象的值是否相等
is not
python整数缓存范围【-5,256】
定义多点坐标_绘出折现
少用加号
数据组织方式
一组数据如何保存 数据结构
抽象数据类型:确定数据组织形式,数据上的一组操作,只有相应的接口。
引用:变量=通过对象的地址引用了对象
对象位于堆内存
变量位于栈内存
