

如何减轻过拟合?Regularization泛化
Occam's Razor:
more thing should not be uesd than are necessary 任何不必要的都不需要
1、提供更多的数据——这是代价做大、也是最困难的方法;
2、简化模型
shallow模型不需要用太复杂的,尤其是当数据集有限的时候。shallow是一个相对的概念,跟数据集大小和网络的复杂度有关。
regularization
我们一开始的目标是最小化交叉熵,下面是目标函数:
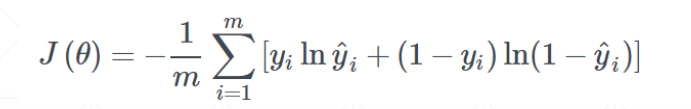
但经过训练之后,为了增强模型的表达能力,很可能出现一个7次方的函数式
接下来我们增加一个参数范式,这里的参数有w1,b1,w2,b2等等
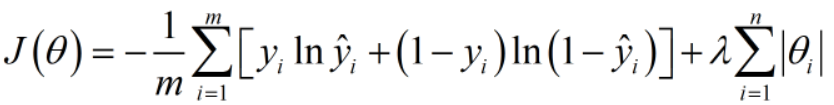
可以是一范数,可以是二范数。
优势1:当我们的总目标是尽可能小化J(Q)时,一范式参数值也会尽可能得小,总体来说会使我们的模型更加平缓和稳定,更加具有总体数据代表性。
优势2:会简化模型,有可能将高次方模型转变为低次方模型,同时还能保持模型的表达性
常用的有一范式和二范式

L2_regularization

这个wieght_decay是二范式的参数值,传入这个参数就可以以二范式进行泛化了
L1_regularization
现阶段没有参数一范数的现成代码,需要自己敲

3、Dropout——增加鲁棒性
4、Data argumentation——数据增强
5、Early Stopping——提前终结
