DWD:判空过滤,维度退化(降维)


22人加入学习
(0人评价)
该课程属于 1246-谭同学-大数据方向-大数据分析方向:就业:是 请加入后再学习
三范式区分:
1.第一范式核心原则:属性不可切割
2.第二范式核心原则:不能存在“”部分函数依赖“”
3.第三范式核心原则:不能存在传递函数依赖
范式理论(重点)
函数依赖:
完全函数依赖
部分函数依赖
传递函数依赖
insert into table ads_user_retention_day_rate
select
from
(
)
留存用户:某段时间内的新增用户(活跃用户),经过一段时间后,又继续使用应用的被认作是流程用户
流程率:留存用户占当时新增用户(活跃用户)的比例即是留存率
脚本:
定义数据库名称
hive地址
date -d "-1 day" + %F
%F格式:2017-10-28
每月活跃设备分析
date_format(dt,'yyyy-MM')=date_format(dt,'yyyy-MM')
每周活跃设备分析:
累计每日活跃用户数并去重
date_add(next_day('2019-02-10','MO'),-7)
强制删表:cascade
函数运用:
collect_set
日期函数:
date_format():
date_add():
next_day():
last_day():当月最后一天
一、自定义UDTF函数使用
lateral view()
二、自定义UDTF函数,需要继承genericUDTF:重写initiallize();process():close()
从JSON对象中取值
脚本:
导入hdfs上的数据到hive表
脚本中需指定数据库mingchen
hive优化:
使用Tez引擎,jians
Tez运行引擎,性能优于Mr,数据传输不落入磁盘
awk:一种处理文本文件的语言
$ awk '{print $1,$4}' log.txt
selector:logType
1.获取body中数据
event.getBody():
2.区分类型
ETL拦截器
定义intercept
1.获取数据
byte[] body = event.getBody();
String json = new String(body);
2.校验数据是否合法
定义logUtils类封装校验逻辑
NumberUtils.isDigits()判断是否纯数字
flume:
TAILDIR:支持断点续传
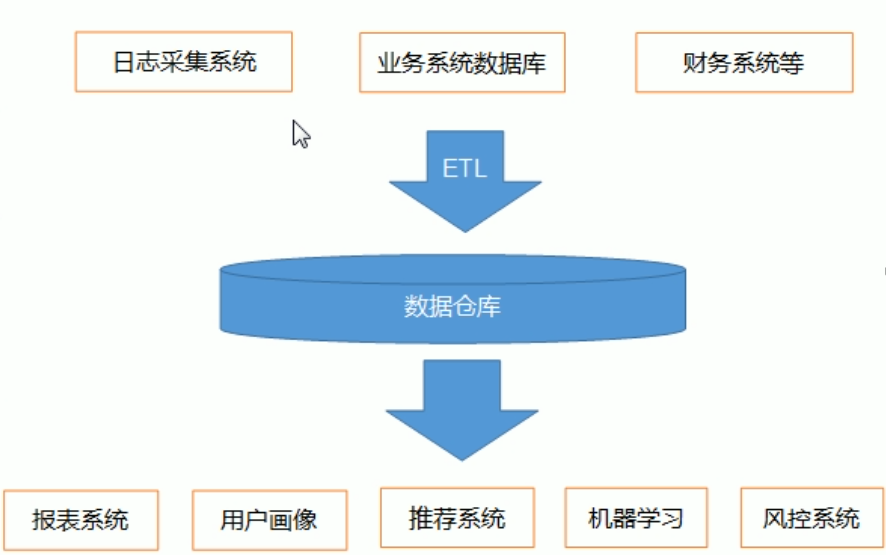
数据仓库,是为企业所有决策制定过程,提供所有系统数据支持的战略集合。
通过对数据仓库中数据的分析,可以帮助企业,改进业务流程、控制成本、提高产品质量等。
对数据的处理爆发阔:清洗、转义、分类、重组合并、拆分、统计等
hadoop集群的常见端口号:50070、50090、9000、8088、19888
核心配置文件:core.site
两个必备条件:Java、ssh

课程特色
考试(7)
图文(1)
视频(89)