weight sharing:权重共享,类似于CNN,局部信息--以此减少网络参数量


1人加入学习
(0人评价)
该课程属于 2393-段同学-算法方向-计算机视觉-就业:否 请加入后再学习
image normalization:把数据都放到0的附近,这样损失函数的梯度就不会变为0
对RGB图像进行卷积的话kernel=[3,3,3]
K为一个3*3的卷积核,(即:维度为3,3)因为要分别对R,G,B进行卷积,所以有3个通道
multi-k:[a,b,c,d]
a:表示用了几种类型的kernel,比如用于边缘检测的--edge AND 用于模糊的blur这就是2个kernel
b:输入图像的通道数
每个kernel 都会带一个偏置bias的值==a‘
output是几个,a就是几
Stride:表示移动的步长
Padding:表示打了几行补丁,如果输出的图像不满意,可以加行列

weight_decay=0.01 相当于拉姆达的值
防止过拟合:
把一个数据集分为train_loader and test_loader,训练模型来对test_loader进行测试,目的是在过拟合之前选取最优模型参数,提前终止train
API:
1.nn.Model--都要大写:nn.Linear/nn.Relu
2.F.relu and F.cross-entropy的API
小写
O1k:节点编号

链式法则
对于y2来说y1是输入量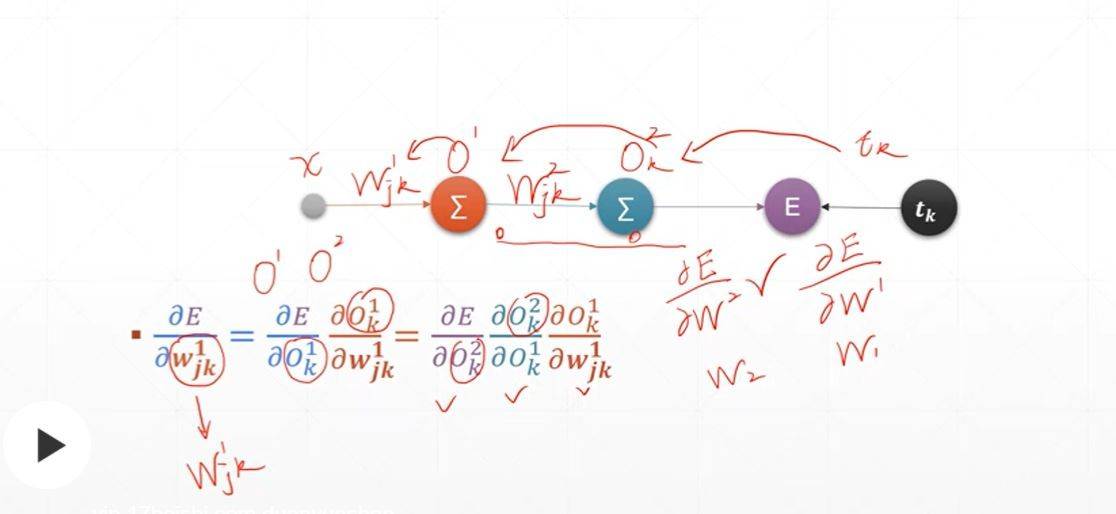
一步一步拆分开
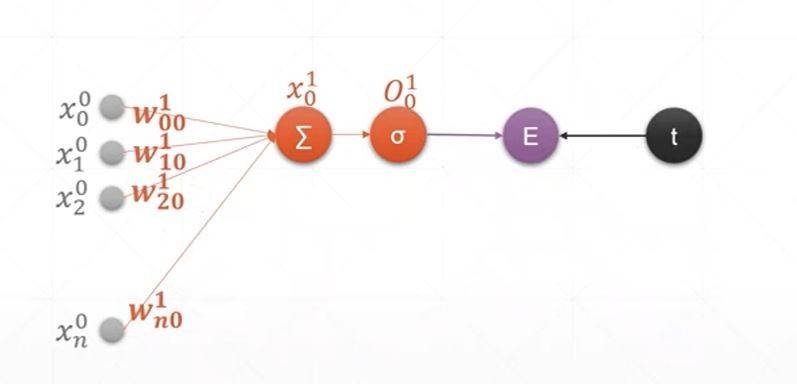
上层是单层感知机
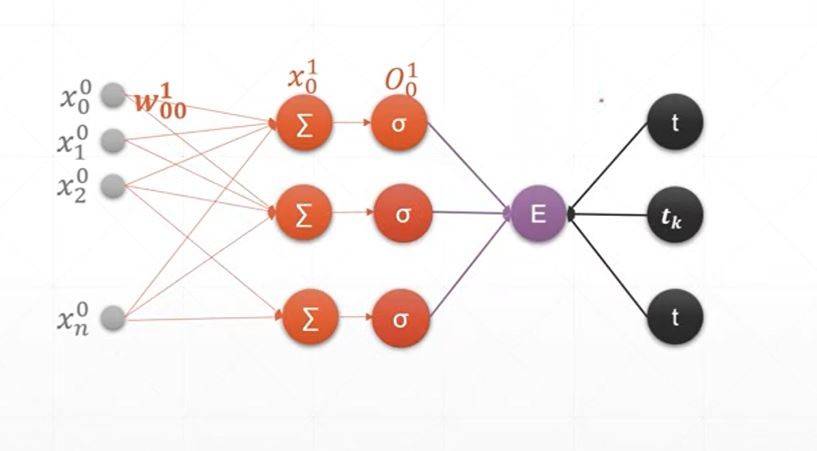
上图是多层感知机

Wij,i是上一层节点编号,j是下一层节点,由于例子中下一层就一个所以j都为0
O10中的1是第一层,0:第0号节点
这个例子只是一层!
激活函数——Loss

上图就是把10维的改为1个维度的

backward:向后传播

softmax函数所有的值都满足0-1;所有概率值相加==1
采用放缩法,把大的放大到更大,小的更小
例如:2.0和1.0——经过softmax之后,变成了0.7,0.2,从原来的2倍
Loss/Loss梯度
Mean Squard Error;MSE—均方差
softmax:
第二个式子要开根号,所以用torch.norm计算的时候,要加上一个pow(2)把平方乘回来
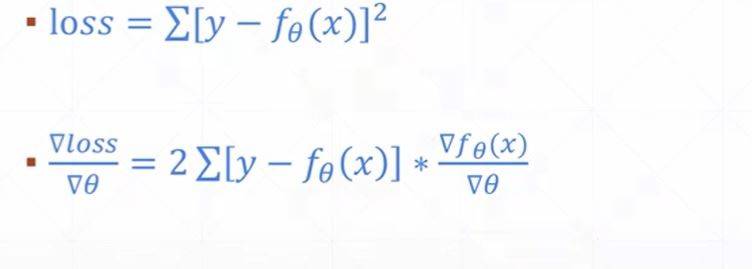
后面那一部分取决于用什么网络结构,对thta求导的地方,取决于选取什么函数
sigmoid:把输出的值压缩到[0,1]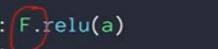
初始化是为了让学习按照正确的方式找到全局点
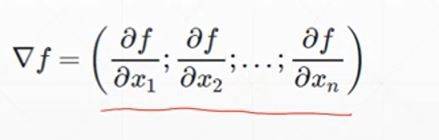
梯度:即为所有偏微分的向量
梯度是向量
导数是标量,偏微分也是标量

有的时候C的来源是很乱的,所以就设置一个condition矩阵,1表示来自A,0表示来自B

设置a内的元素都为0;b内的元素都为1;
cod>0.5的为a,小于0.5的为b
gather:收集

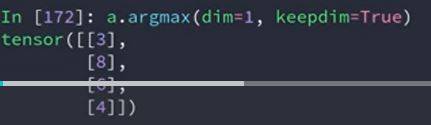
dim and keepdim


topk:返回值最大的前k个值。0.8362对应的值是3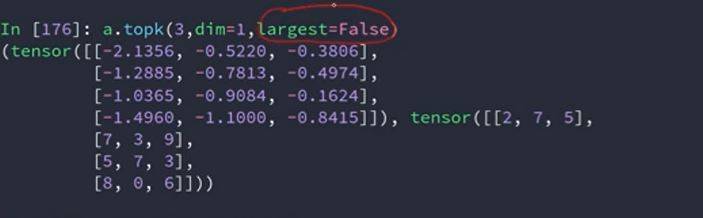
把其中的largest=False就是求概率最小的值,看图中,-2.1356对应2,也就是2是最不可能的值

kvalue表示第k个的value
比较是否相等,相等==1,不等==0
每一个位置相等的话返回Ture
- >二维的矩阵相乘
- matmul
- torch。matmul只会运算后面的2的维度,例如[4,3,28,64] [4,3,64,32]
- 结果等于[4,3,28,32]——4,3可以表示为batch,channel
- pow
- a=torch.full([2,2],3)==a**2
- a.pow(2)
- tensor([9,9 '
- [9,9])
- rsqrt——平方的倒数
- 近似值:a.floor—往下取值;a.ceil()—向上取值
- eg:a=torch.tensor(3.14)
- a.floor()==tensor(3.)
- a.ceil()==tensor(4.)
- a.trunc()==tensor(3.)
- a.frac()==tensor(0.1400))
- a.round()==tensor(3.)
- a=torch.tensor(3.5)
- a.round()==tensor(4.)
- clamp裁剪功能
- 下图中是把小于10的数全变为10
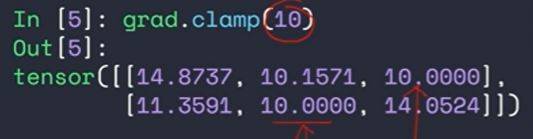
下图中设置的是最大值九尾10
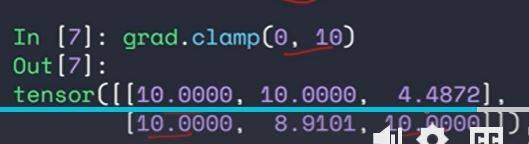
- 1.basic
- sub--减
- mul--乘法
- div--除
- 按照矩阵形式相乘:
- Torch.mm--适合于2D
- Torch.matmul OR @
- 对图片进行降维:eg---[4,784] @[784,512],这两个矩阵相乘,就可以把维度从784降到512
- pytorch的写法是:w=torch.rand(512,784)——512是输出的维度,784是输入的维度
- 但是为了完成矩阵相乘的任务,就乘以w的转置即:(x@w.t()).shape

授课教师
高级算法工程师
课程特色
考试(9)
图文(1)
视频(151)