机器学习调参基本思想
调参目标是提升某个模型评估指标
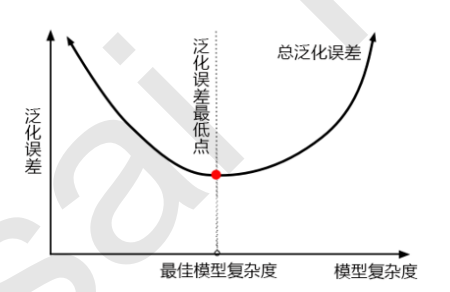
1、泛化误差(衡量模型在未知数据上准确率的指标)
1)在测试集上表现不好:泛化能力不够
2)泛化误差受模型结构(复杂度)影响(U型曲线),调参之前,判断模型在曲线哪个部分
3)模型太简单或太复杂,泛化误差都会升高,追求的是中间的平衡点
4)模型太复杂:过拟合,太简单:欠拟合
5)树模型和树的集成模型,越深、枝叶越多、模型越复杂
6)树模型和树的集成模型目标:减少模型复杂度(剪枝),使模型向图像左边移动
2、各个参数对树模型的影响程度(由大到小)
1)n_estimators:计算量允许,越大越好,不影响单个模型复杂度
2)max_depth:默认让树生长到最茂盛,下降,模型更简单
3)min_samples_leaf、min_samples_split:默认最小限制1、2,即最高复杂度,调大,模型更简单
4)max_features:默认特征总数开平方(auto),中间复杂度,减小,更简单,增加,更复杂(不怎么用)
5)criterion:一般选gini(影响看具体情况)