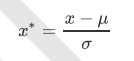数据预处理与特征工程
数据挖掘的五大流程:获取数据、数据预处理、特征工程、建模、上线验证
数据预处理preprocessing & impute
一、数据无量纲化(统一规格,特例:决策树、树的集成算法不需要)
1、中心化 zero-centered/mean subtraction
本质是所有记录减去一个固定值
1)preprocessing.MinMaxScaler
- 数据归一化Normalization:数据收敛到[0,1]之间,归一化后的数据服从正态分布
- 参数feature_range:控制缩放范围,默认[0,1]
-
如何用numpy实现归一化?使用公式
import numpy as np
x=[[-1,2],[-0.5,6],[0,10],[1,18]]
x=np.array(x)#转成数组
#归一化
x_nor=(x-x.min(axis=0))/(x.max(axis=0)-x.min(axis=0))
x_nor
2)preprocessing.StandardScaler
- 数据标准化Standardization/Z-score normalization:把数据变成标准正态分布(均值为0,方差为1)
- 标准化训练完查看均值和方差的属性?(自动按列计算)
scaler.mean_
scaler.var_
3)如何选择?
- 归一化对异常值敏感,一般选标准化
- 不涉及协方差计算、需要压缩到某个区间:归一化
- 只压缩,不中心化:MaxAbsScaler
- 异常值多、噪声大分位数RobustScaler
2、缩放处理 scale
本质是所有记录除以一个固定值