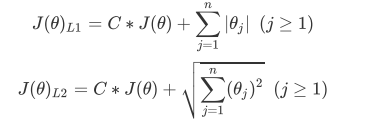逻辑回归
一、概述
1、逻辑回归是用于分类的回归算法,可做二分类,也可做多分类
2、逻辑回归的sigmoid函数(记住公式和图像)
z越大g(z)越靠近1,z越小g(z)越靠近0,将任何数据压缩到(0,1)
3、逻辑回归的优点:对线性关系拟合效果极好;计算速度快;返回不是固定0、1,而是小数形式类概率数字
4、目的是求解使模型拟合效果最好的参数,方式是梯度下降SGD
二、linear_model.LogisticRegression
1、损失函数:求解最优参数的工具,用来衡量参数为θ的模型拟合训练集产生的信息损失的大小。
追求损失函数最小化的参数组合。(不求解参数的模型就没有损失函数,比如KNN,决策树)
对逻辑回归过拟合的控制,通过正则化实现。
2、控制过拟合的两个参数
1)penalty
默认="l2",若选择"l1”,参数solver只能使用"liblinear"和"saga"
l1正则化会把参数压缩到0,本质特征选择,越强、0越多、参数越稀疏,防止过拟合。数据维度高:l1正则化。
l2正则化只会让参数尽量小,不会取到0。
2)C:正则化强度导数默认1.0(正则项:损失函数=1:1),越小,对模型惩罚越大,正则化强度越大。
3、重要属性
1)coef_:每个特征对应参数
逻辑回归模型评估指标
metric.confusion_matrix
metric.roc_auc_score
metric.accuracy_score
1、向量一般写成列向量
2、模型属性都是在fit之后查看
3、np.linspace(start,end,num)包括end
4、predict返回的是一个预测的值,predict_proba返回的是对于预测为各个类别的概率
5、