

SVD比PCA快得多
一、2个重要参数
1、svd_solver
"auto":数据量小选full,大则选randomized
"full":生成完整的矩阵,数据量不大一般选用
"randomized":适合特征矩阵巨大,计算量大。
"arpack”:适合特征矩阵大,一般用于特征矩阵为稀疏矩阵(每一列为0,1组成,大部分为0)
注:一般选"auto", 算不出来找"randomized"
2、random_state:
svd_solver为"randomized""arpack”生效
SVD比PCA快得多
一、2个重要参数
1、svd_solver
"auto":数据量小选full,大则选randomized
"full":生成完整的矩阵,数据量不大一般选用
"randomized":适合特征矩阵巨大,计算量大。
"arpack”:适合特征矩阵大,一般用于特征矩阵为稀疏矩阵(每一列为0,1组成,大部分为0)
注:一般选"auto", 算不出来找"randomized"
2、random_state:
svd_solver为"randomized""arpack”生效
PVC中的SVD
重要参数svd_solver 与 random_state
"auto":基于X.shape和n_components的默认策略来选择分解器:如果输入数据的尺寸大于500x500且要提 取的特征数小于数据最小维度min(X.shape)的80%,就启用效率更高的”randomized“方法。否则,精确完整 的SVD将被计算,截断将会在矩阵被分解完成后有选择地发生。
"full":从scipy.linalg.svd中调用标准的LAPACK分解器来生成精确完整的SVD,适合数据量比较适中,计算时 间充足的情况,生成的精确完整的SVD的结构为:
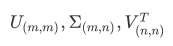
"arpack":从scipy.sparse.linalg.svds调用ARPACK分解器来运行截断奇异值分解(SVD truncated),分解时就将特征数量降到n_components中输入的数值k,可以加快运算速度,适合特征矩阵很大的时候,但一般用于 特征矩阵为稀疏矩阵的情况,此过程包含一定的随机性。截断后的SVD分解出的结构为:
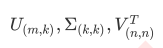
"randomized",通过Halko等人的随机方法进行随机SVD。在"full"方法中,分解器会根据原始数据和输入的 n_components值去计算和寻找符合需求的新特征向量,但是在"randomized"方法中,分解器会先生成多个随机向量,然后一一去检测这些随机向量中是否有任何一个符合我们的分解需求,如果符合,就保留这个随 机向量,并基于这个随机向量来构建后续的向量空间。这个方法已经被Halko等人证明,比"full"模式下计算快 很多,并且还能够保证模型运行效果。适合特征矩阵巨大,计算量庞大的情况。