强化学习和生成式对抗网络
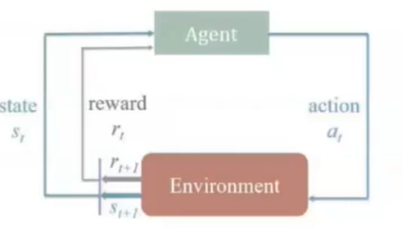
强化学习:机器学习分支;自行解决决策问题,并且能够强化连续决策;
组成部分:
1、代理;
2、环境;
3、行动;
4、奖励;
学习任务:
1、篇幅型;
有间断
2、永久型;
没有间断
学习方式:
value baed
写出一个value function,这个value function可以告诉我们每一步的未来rewards会有多大;
policy based
在这里我们希望最优化一个policy function而不是一个value funtion;
有两种policy可以选择:
Deterministic:相同state下,永远给出相同的action。简单来讲就是每次在同样的情况下作出一样的选择;
Stochastic:给出一个所有action的可能性的distribution,意思是选择具有随机性,在某些对抗性游戏中,随机决策是必须的;
GAN
生成模型;判别模型;
分类:
1、根据当前数据得到一个数据分布:数据回归;
2、根据当前的数据生成一个新的图片;
用途:
1、补缺数据;
2、数据是否符合生成的规律;
3、

最大似然机构:
生成对抗模型:
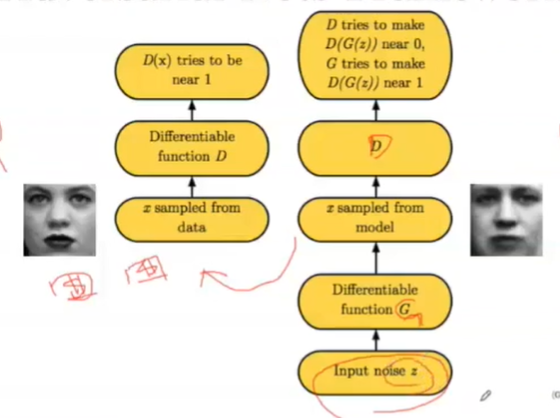

要求:必须是可导的:
DCGAN:反卷积,
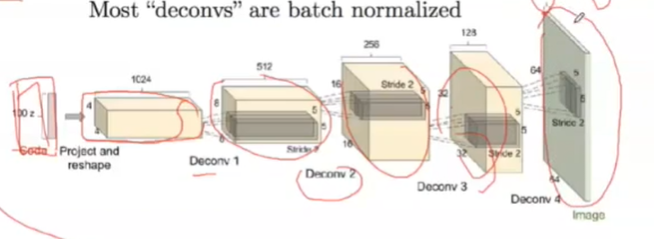
由低维到达高维的;
风格转移:
循环机构,