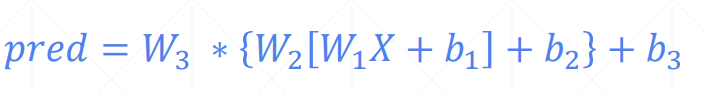
Non-linear Factor
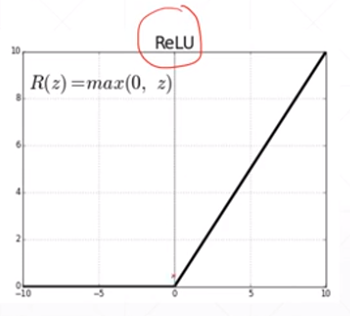
加入激活函数之后

pred既有线性表达能力,还有非线性的表达能力



Non-linear Factor
加入激活函数之后
pred既有线性表达能力,还有非线性的表达能力
写代码开发的工作,做为一场战争的话,
写出来的代码,相当于士兵与武器
故,数据结构与算法是一名程序开发人员的必备的基本功,不是一
算法,就是让计算机把问题解决出来,计算的方法
算法是计算机处理信息的本质,因为计算机程序本质是一个算法来告诉计算机确切的步骤来执行一个指定的任务。
一般地,当算法在处理信息时,会从输入设备或数据的存储地址读取数据,把结果写入输出设备或某个存储地址供以后再调用
算法是独立存在的一种解决问题的方法与思想
对于算法而言,实现的语言并不重要,重要的是思想。
算法可以有不同的语言描述实现版本(如C描述,C++描述,python描述等),我们现在是在python语言进行描述实现
算法的五大特性:
输入:算法具有0个或多个输入
输出:算法至少有1个或多个输出
有穷性:算法在有限的步骤之后会自动结束而不会无限循环,并且每一个步骤可以在接受的时间内完成
确定性:算法中的每一步都有确定的含义,不会出现二义性
可行性:算法的每一步都是可行的,也就是说每一步都能够执行有限的次数完成
Expand/repeat
Expand——broadcasting仅仅是把数据进行了传播,节约内存
仅仅局限于从1开始扩展,如果是从3拓展的话,是不可行的,会报错
Repeat——实实在在的数据拷贝
squeeze、unsqueeze
for example
数据的存储、维度顺序非常重要,需要时刻谨记
索引与切片
4、rand、rand_like、randint
rand随机生成在[0, 1]的数值
rand_like是先把rand生成的数组读取出来再喂给rand函数
randint需要给出最大值、最小值和shape
创建tensor
(1)从numpy进行导入
(2)从list里面导入
小写的tensor括号里接收的是现有数据,而大写Terson、FloatTensor里面接受的是形状,也可以接受现成的数据,括号里用中括号时表示现成的数据,括号时输入的形状
Dim1
一般会用在bias、线性层的输入
Dim2
一般用在batch,当输入多张图片时,第一个数字是图片的个数,第二个是打平图片之后的一维点数
Dim3
适合RNN的文字处理
Dim4
适合CNN
第一个数字是图片的个数,第二个数字是图片的通道,通道为1是灰色图像,通道为3的是菜色图像,后两位数字28*28是minis数据集的长和宽
pytorch中的数据类型

没有对string的支持内键
how to denote string
(1)One-hot并不体现语义
(2)Embedding—word2vec
核实数据类型
数据类型
(1)标量

需要四步:
(1)load data
(2)build model
(3)train
(4)test
控制流程:顺序、条件、循环
回归问题实战
(1)先计算总损失值
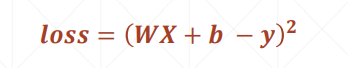
(2)然后计算w和b的偏导,进而更新梯度值
linear Regression——我们要估计连续函数的值;
logistic Regression——在上述linear regression的基础上增加了一个激活函数,把y的空间压缩到0-1的范围,0-1可以表示一个概率
classification——所有的可能性概率之和为1
梯度下降法
pytorch的功能:
(1)CPU加速;
没有显卡,用不了cuda
(2)自动求导*非常重要,因为深度学习本质上就是在利用梯度下降法来求最优解;
(3)常用网络层


静态图:
define——>run
在最开始就需要定义好公式,给定输入值,得到输出值,而且在运行的过程中无法进行调整

动态图:
可以随时调整公式
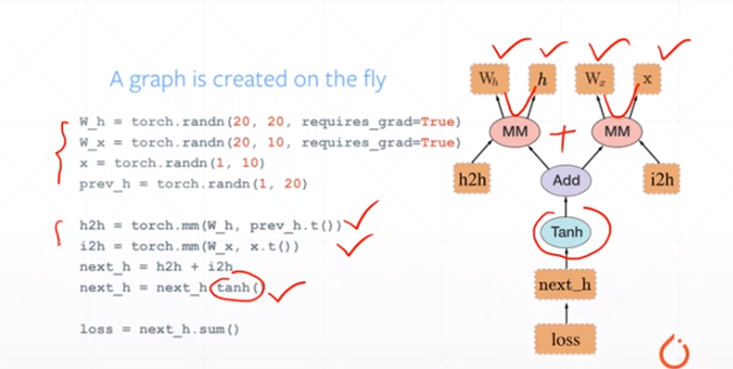

误差来源于两个——一个是bias,还有一个是variance。出现bias是由于开始就没有瞄准靶心;出现vaiance是由于瞄准了靶心,但是发射的时候出现了偏离。我们的目标是低bias和低variance。
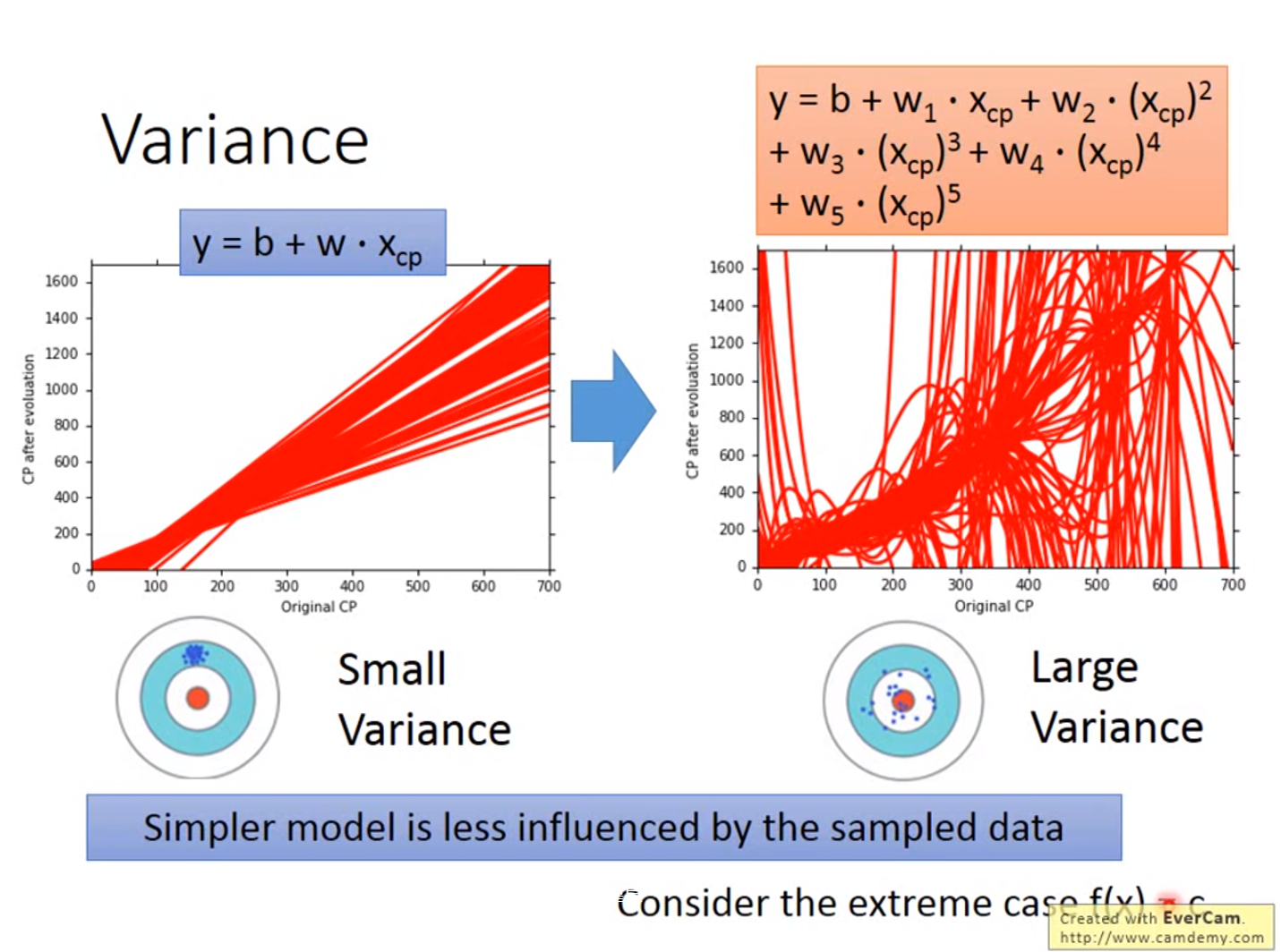
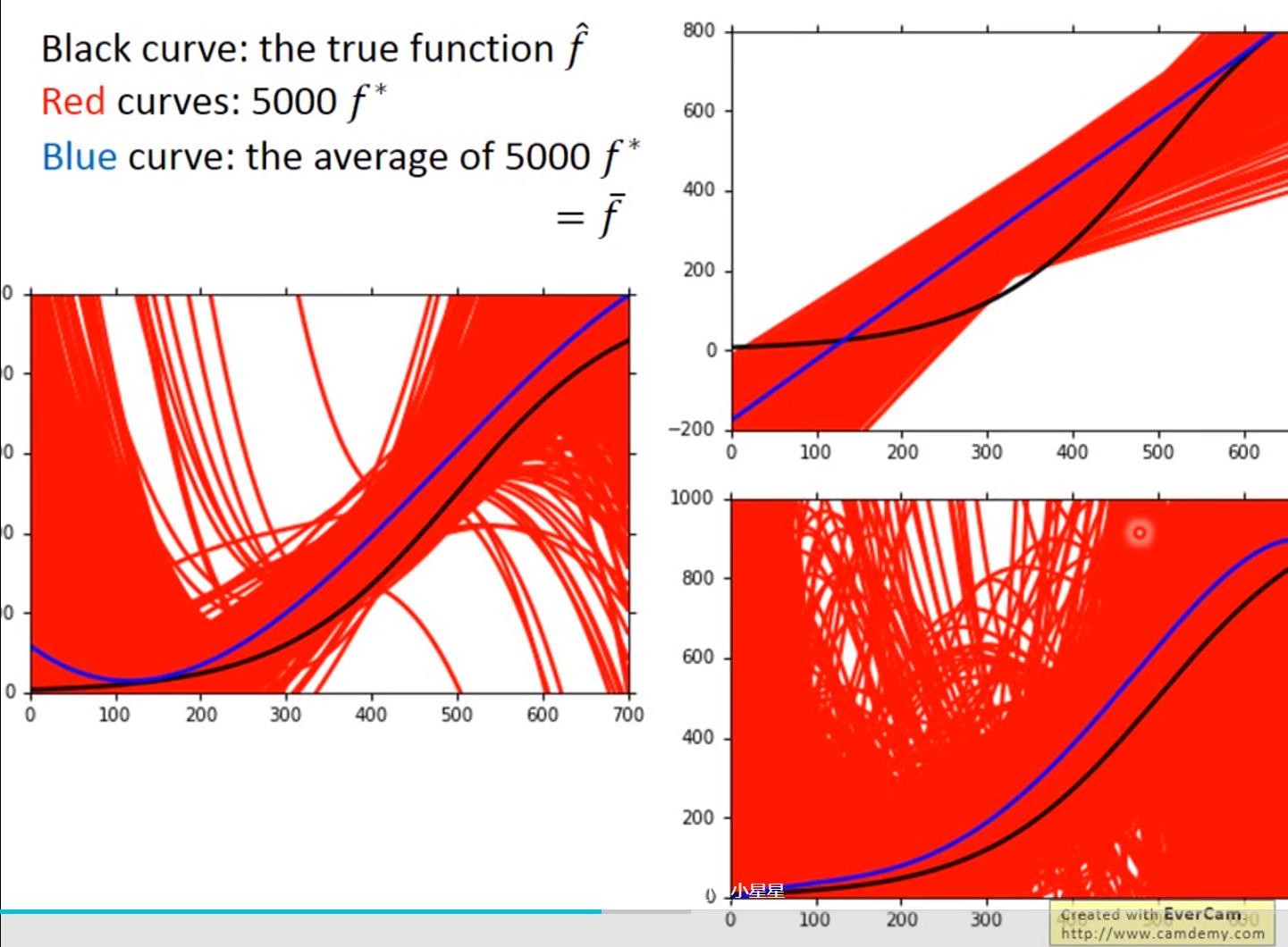
红色的部分是分别在考虑输入值一次方、三次方和五次方函数进行5000次实验的结果,蓝色的线条是将5000次实验结果进行平均即结果
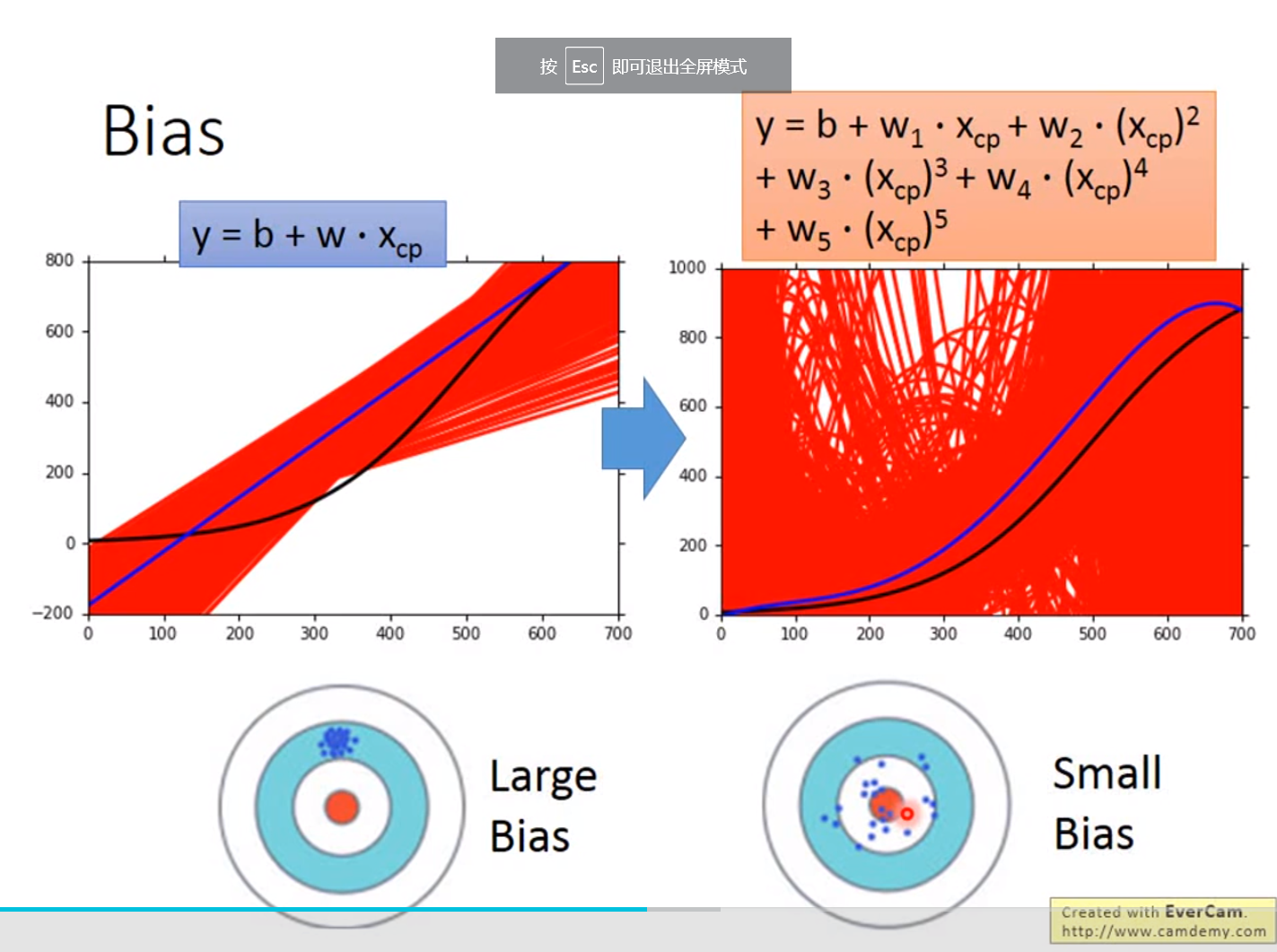

越简单的模型,bias越大,variance比较小;反之,模型越复杂,variance越大,但是平均值却比较接近于期望值
bias较大的情况,问题出现在underfitting;
variance较大的情况,问题出现在overfitting
Diagnosis:
(1)当模型不能拟合训练集时,我们有较大的bias;
(2)当模型可以集合训练集,但是在测试集上出现了较大的损失值,则很大可能上有较大的variance
for bias, redesign模型:
(1)add more feature as input
(2)a more complex model
for variance
(1)more data(增加每次实验的样本量)
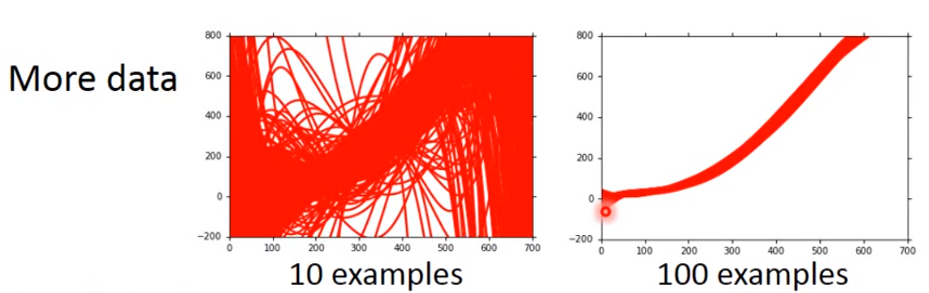
(2)Regularization我们希望曲线越平缓越好

伤害:只包含了比较平滑的曲线,在取值上产生了较大的bias
model selection:
我们想要找到尽可能小的bias和variance来得到最小的损失值
Regression回归
1、应用场景
(1)Stock Market Forecast
(2)Self-driving Car
(3)Recommendation
2、步骤
(1)给一个Model
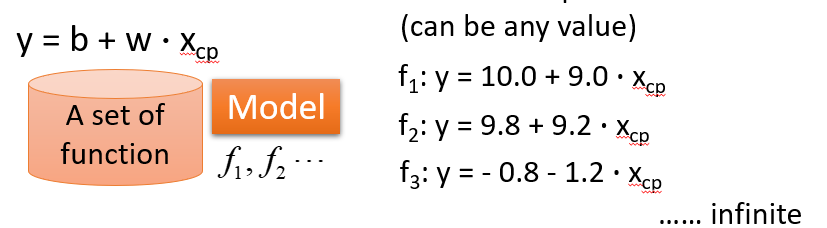
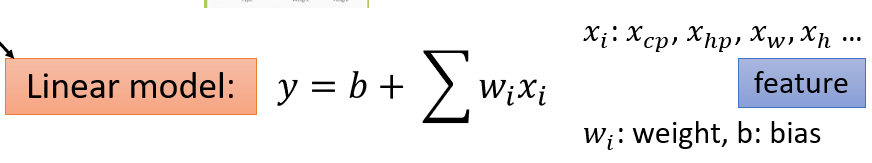
(2)Goodness of Function(函数优度)
输入:a function一个函数
输出:loss funchtion——how bad it is
 Pick the “Best”Function
Pick the “Best”Function
(3)Gradient Descent
梯度下降:初试化w和b这两个参数,不断迭代更新,知道找到最优解,也就是使损失值达到最小的参数值

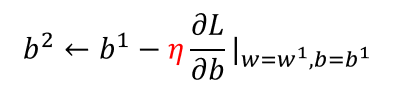
在线性回归里,是不需要担心找不到全局最优解的,因为其三维图形是一圈一圈的等高线,不管从哪个方向都可以找到最优解
how's the results?
训练的目的是损失值最小,但是通过训练集得到的损失值是比测试集得到的损失值小的,为了减少误差,我们需要改进模型——引入了二次方、三侧方和四次方的函数
overfitting——更复杂的模型会得到更不好的结果,所以模型并不是越复杂越好。
what are the hidden factors——pokemon的物种会影响他们值


根据不同的输入值,对不同的物种设置不同 的权重,此时仅设置了输入值的一次方,还可以考虑输入值的二次方函数
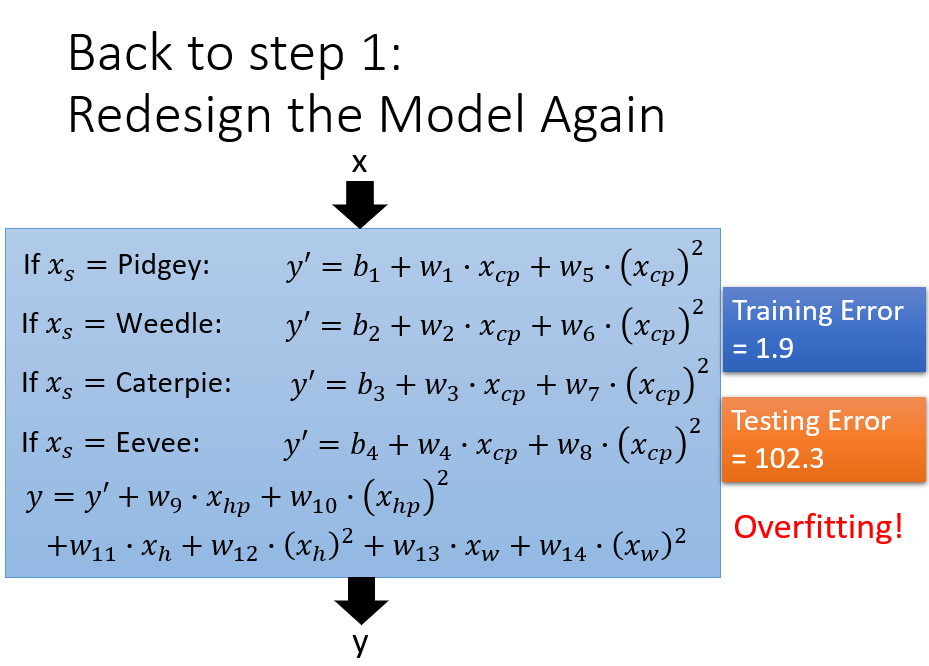
产生了过拟合的结果

设置较为平缓的曲线,由于w的值大于零小于1,当其越接近于0,结果是越为平缓的,前面的系数越大,代表我们越考虑smooth,越可以较多得关注参数w本身的值