双分支
if 条件表达式:
语句1
else:
语句2
三元条件运算符
简单双分支赋值情况
条件为真时的值 if (条件表达式) else 条件为假时的值
print('s<10' if 5<10 else 's>=10')


双分支
if 条件表达式:
语句1
else:
语句2
三元条件运算符
简单双分支赋值情况
条件为真时的值 if (条件表达式) else 条件为假时的值
print('s<10' if 5<10 else 's>=10')
选择结构
选择结构:单分支、双分支、多分支。
单分支
if 条件表达式:
语句
num=input('请输入一个数字:')
if int(num)>10:
print(num)
条件表达式详解
False、空序列、空值、0、空迭代对象
其他均为True
条件表达式不能出现=,==表示等于判断
控制语句
数据可以看做是‘砖块’。控制语句是代码的组织方式,可以看做是‘混凝土’。
集合
集合无序可变,元素不能重复。实际上,集合底层是字典实现,只有字典的‘键对象’。因此是不能重复且唯一的。
集合创建和删除
1. 使用{}创建,并使用add()方法添加元素
a={3,5,7}
a.add(9)
print(a)
2. 使用set(),将元组、列表等可迭代对象转成集合
3.remove()删除指定元素,clear()清空整个集合
集合相关操作
a|b #并集
a.union(b)
a&b #交集
a.intersection(b)
a-b #差集
a.difference(b)
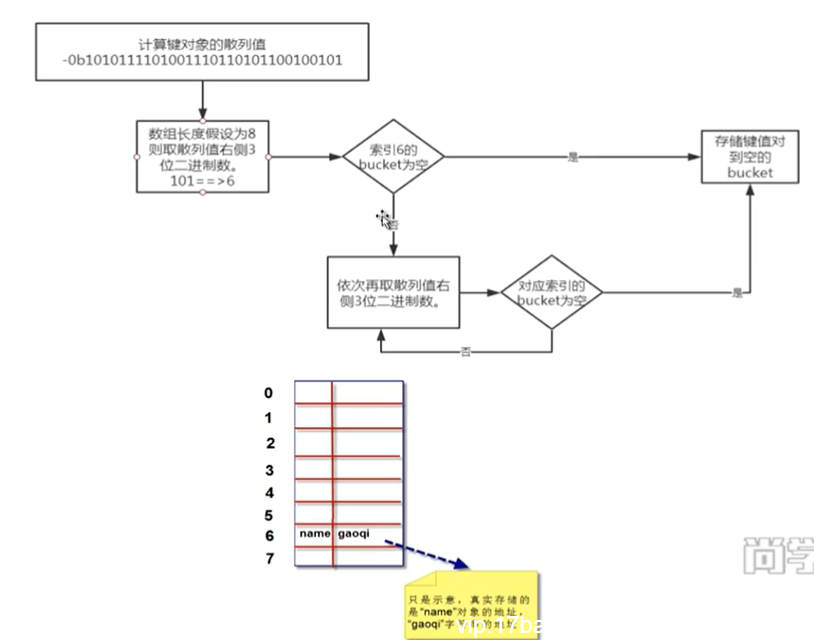
根据键查找‘键值对’的底层过程
a.get('name')
第一步,我们计算'name'对象的散列值:
bin(hash('name'))
和存储的底层流程算法一致。取散列值不同位置的数字,然后查看偏移量对应的bucket是否为空。如果为空,返回None。如果不为空,则将这个bucket的键对象计算对应散列值,和我们的散列值进行比较。相等则返回对应'值对象'。不相等,则重新计算偏移量。依次取完后仍然没找到,则返回None。


字典核心底层原理(重要)
字典对象的核心是散列表。散列表是一个稀疏数组(总有空白元素的数组)。数组的每个单元叫做bucket。每个bucket有两部分:一个是键对象的引用,一个是值对象的引用。通过偏移量来读取指定bucket。
将一个键值对放进字典的底层过程
第一步计算key的散列值。Python中可以通过hash()来计算。
拿出计算出的散列值的最后面3位数‘101’作为偏移量,十进制是数字5。我们查看偏移量5对应的bucket是否为空。则把键值对放进去。如果不为空,则依次取后面3位作为偏移量,直到找到为空的bucket将键值对放进去。
复杂表格数据存储
表格数据使用字典和列表存储,并实现访问。
r1={'name':'ben','age':18,'city':'BJ'}
r2={'name':'joe','age':19,'city':'SH'}
r3={'name':'cici','age':20,'city':'SZ'}
tb=[r1,r2,r3]
#获得第二行人的城市
print(tb[1].get('city'))
#打印所有的薪资
for i in range(len(tb)):
print(tb[i].get('city'))
#打印表的所有数据
for i in range(len(tb)):
print(tb[i].get('name'),tb[i].get('age'),tb[i].get('city'))
序列解包
序列解包可以用于元祖、列表、字典,对多个变量赋值。
x,y,z=(20,30,10)
(a,b,c)=(20,30,10)
[a,b,c]=(20,30,10)
字典序列解包
s={'name':'ben','age':18,'sex':'man'}
a,b,c=s #接收键
e,d,f=s.values() #接收值
h,i,j=s.items() #接收键值对
字典元素添加、修改、删除
1.给字典新增'键值对'。如果'键'已经存在,则覆盖旧得键。如果键不存在,则新增'键值对'。
a={'name':'lynn','age':18,'job':'planner'}
a['add']='南京路1号'
a['age']=16
print(a)
2.使用update()将新字典中所有键值对全部添加到旧字典对象上。如果key有重复,直接覆盖。
a={'name':'lynn','age':18,'job':'planner'}
b={'name':'ben','age':120,'sex':'man'}
a.update(b)
print(a)
3.字典中元素的删除,可以用del()或者clear()全删;pop()删除指定键值对,并返回对应的'值对象'。
b=a.pop('age')
4.popitem()随机删除和返回该键值对
a.popitem()
字典元素的访问
为了测试各种访问方法,我们这里设定一个字典对象:
a={'name':'lynn','age':18,'job':'planner'}
1. 通过[键]获得'值'。若键不存在,则抛出异常
a={'name':'lynn','age':18,'job':'planner'}
print(a['name'])
2.通过get()方法获得值,推荐使用。优点:指定键不存在,返回None;也可以设定指定键不存在时默认返回的对象。推荐使用get()获取'值对象'。
a={'name':'lynn','age':18,'job':'planner'}
a.get('name')
print(a.get('sex','女'))
3.列出所有键值对
a.items()
4.列出所有的键,列出所有的值
a.keys()
a.values()
5.len()键值对的个数
6.检测一个'键'是否在字典中
print('name' in a)
列表切片操作
典型操作
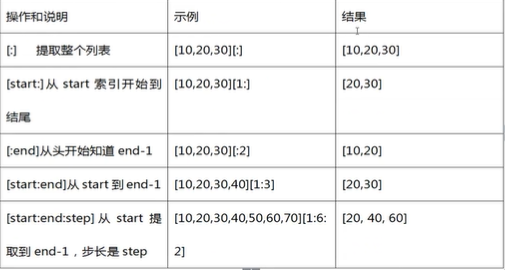
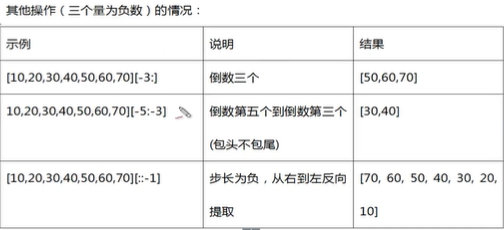
切片不在范围内也不会报错。起始偏移量小于0则会被当成0,终止偏移量大于长度-1则会被当成长度-1
列表遍历
for obj in listObj:
print(obj)
生成器推导式创建元组
生成器推导式用的小括号。生成器生成生成器对象,再转化成元组。
s=(x*2 for x in range(5))
print(tuple(s)) #只能访问一次元素,第二次就为空了。需要再生成一次。
print(s._next_()) #指针下移
元组可以作为字典的键,列表不行。
元组的元素访问和计数
1. 元组的元素不能修改
2.访问和列表一样,返回的仍然是元组
3.如果要对元组排序,只能用sorted()生成新的列表对象
Zip
将多个列表对应位置的元素组合成为元组,并返回这个zip对象。
元组tuple
可以修改列表中的元素,元组属于不可变序列。
元组支持如下操作:
1. 索引访问
2. 切片操作
3. 连接操作
4. 成员关系操作
5. 比较运算操作
6. 计数
元组的创建
1.通过()
a =(10,20,30) #小括号可以省略
a=(20,) #单元素加逗号
2.通过tuple()
b=tuple(可迭代的对象)
元组对象删除 del b
多维列表
二维列表
一维列表帮助存储一维、线性的数据。
二维列表帮助存储二维、表格的数据。
a=[
['高一',18,3000,'北京']
['高二',17,2000,'上海']
['高三',19,1000,'深圳']
]
print(a[0][3])
嵌套循环打印二维列表的所有数据
a=[
['高一',18,3000,'北京']
['高二',17,2000,'上海']
['高三',19,1000,'深圳']
]
for m in range(3):
for n in range(4):
print(a[m][n],end='\t')
print()#打印完一行,换行
列表排序
修改原列表,不生成新列表的排序
a=[40,10,20,30]
a.sort() #默认升序
a.sort(reverse=True) #降序排列
import random
random.shuffle(a) #随机打乱顺序
建新列表的排序
内置函数sorted(),这个方法返回新列表,不对原列表修改
a=[40,10,20,30]
a=sorted()
c=sorted(a,reverse=True)
reversed()返回迭代器
内置函数reversed()也支持逆序排列,不对原列表做修改。
max和min
返回列表中的最大最小值
sum
对数值型列表所有列表求和,非数值型报错
列表元素访问和计数
通过索引直接访问元素
索引区间[0,列表长度-1],超过范围则报错
index()获得指定元素在列表中首次出现的索引
index(value,[start,[end]])
a=[10,20,30,40,50]
a.index(50,3)
count()获得指定元素在列表中出现的次数
a=[10,20,30,20,50]
a.count(20)
len()返回列表长度
列表中元素的个数
成员资格判断
in关键字判断
a=[10,20,30,40,50]
20 in a
列表元素的删除
del删除
删除列表指定位置的元素
a=[10,20,30]
del a[1]
print(a)
pop()方法
pop()删除并返回指定位置元素,如果未指定位置则默认操作列表最后一个位置
a=[10,20,30]
b=a.pop()
print(b)
remove()方法
删除首次出现的指定元素,不存在则异常
列表的创建
基本语法[]创建
a=[]
list()创建
list可以将任何可迭代的数据转变成列表
a=list('zifuchuan')
range()创建整数参数
range([start,]end[,step])
start可选,表示起始数字,默认0
end必选,表示结尾数字
step可选,表示步长,默认1
推导式生成列表
a=[x*2 for x in range(5)] #循环创建多个元素
a=[x*2 for x in range(100) if x%9==0] #通过if过滤元素
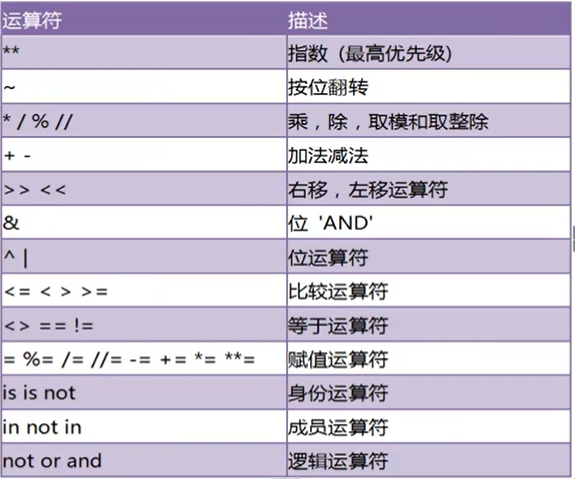
1.比较运算符可以连用
3<a<10
2.位操作
&=按位与
|=按位或
^=按位异
<<左移1位相当于乘以2;左移两位相当于乘以4
>>右移1位相当于除以2;右移两位相当于除以4
运算符优先级问题
复杂表达式一定要使用小括号组织
1.先乘除,后加减
2.位运算和算术运算>比较运算符>赋值运算符