建一棵树
train_test_split
训练集和测试集划分每次都是随机的喔,所以实验结果每次都不同
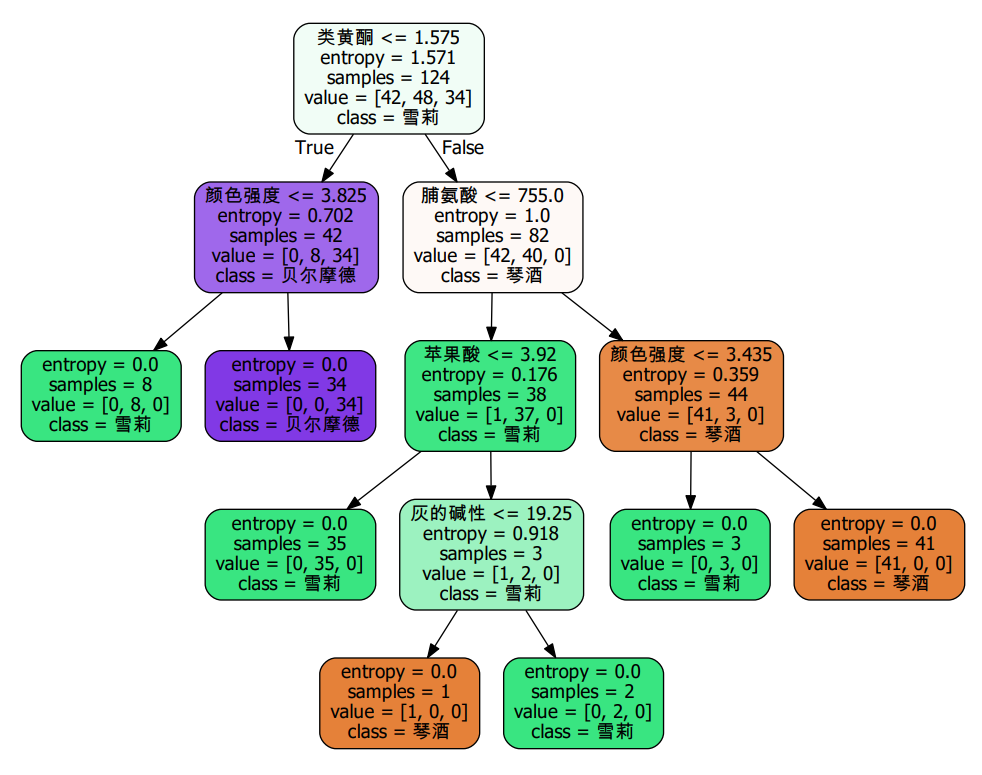
决策树在形成时,分支的时候是通过计算每个节点的不纯度来选取节点,是通过优化每个节点来形成的,但是最优的节点不一定能形成最优的树。
每次建树的时候都是通过选取不同的特征值来形成不同的树。但是每次返回的最优的树都不同。
所以可以通过固定一个种子数来固定最优树模型。
random_state用来设置分枝中的随机模式的参数,默认None,在高维度时随机性会表现更明显,低维度的数据 (比如鸢尾花数据集),随机性几乎不会显现。输入任意整数,会一直长出同一棵树,让模型稳定下来。
splitter也是用来控制决策树中的随机选项的,有两种输入值,输入”best",决策树在分枝时虽然随机,但是还是会 优先选择更重要的特征进行分枝(重要性可以通过属性feature_importances_查看),输入“random",决策树在 分枝时会更加随机,树会因为含有更多的不必要信息而更深更大,并因这些不必要信息而降低对训练集的拟合。
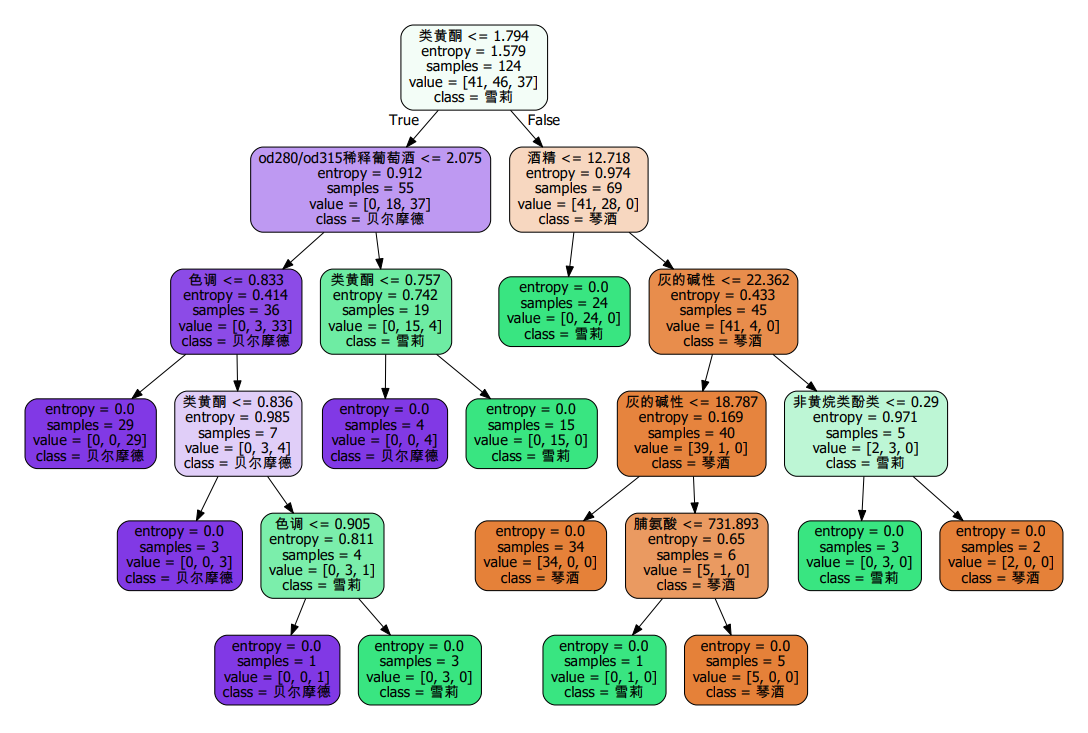
加入splitter=‘random’以后会发现树变得更大更宽了,因为特征值选取更加随机了
默认是best