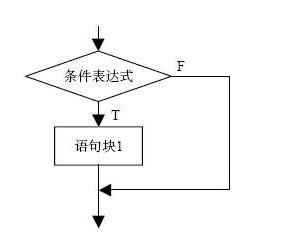
while 循环
while 条件表达式:
循环体语句
num = 0
while num<=10:
print(num)
num += 1
#计算1-100 之间偶数的累加和,计算1-100 之间奇数的累加和。
num = 0
sum_all = 0 #1-100 所有数的累加和
sum_even = 0 #1-100 偶数的累加和
sum_odd = 0 #1-100 奇数的累加和
while num<=100:
sum_all += num
if num%2==0:
sum_even += num
else:
sum_odd += num
num += 1 #迭代,改变条件表达式,使循环趋于结束
print("1-100 所有数的累加和",sum_all)
print("1-100 偶数的累加和",sum_even)
print("1-100 奇数的累加和",sum_odd)