Max pooling 采样取各样区内最大
avg pooling 取平均


Max pooling 采样取各样区内最大
avg pooling 取平均
stride 步长
padding 填充0
layer 层
O' = O - learningrate*gradient
a.shape
数据预处理
深度学习需要的是标准的正方形图片
(1)image resize
(2)Data Argumentation
(3)Normalize
(4)to tensor
自定义数据集实战
test数据量太小的话,测试结果波动较大,所以我们为了保证测试的效果,会把测试集的数据多分配一些
1、load data ——比较重要的模型;
继承一个通用的母类
inherit from torch.utils.data.Dataset
要定一个两个函数
_len_:数据量
_getitiem_:能够得到指定的样本
2、build model——在我们已经定义好的模型上做一些修改;
3、train and test
4、transfer learning
情感分类实战
Google CoLab
(1)continuous 12 hours;
(2)free K80 for GPU;
(3)不需要爬墙
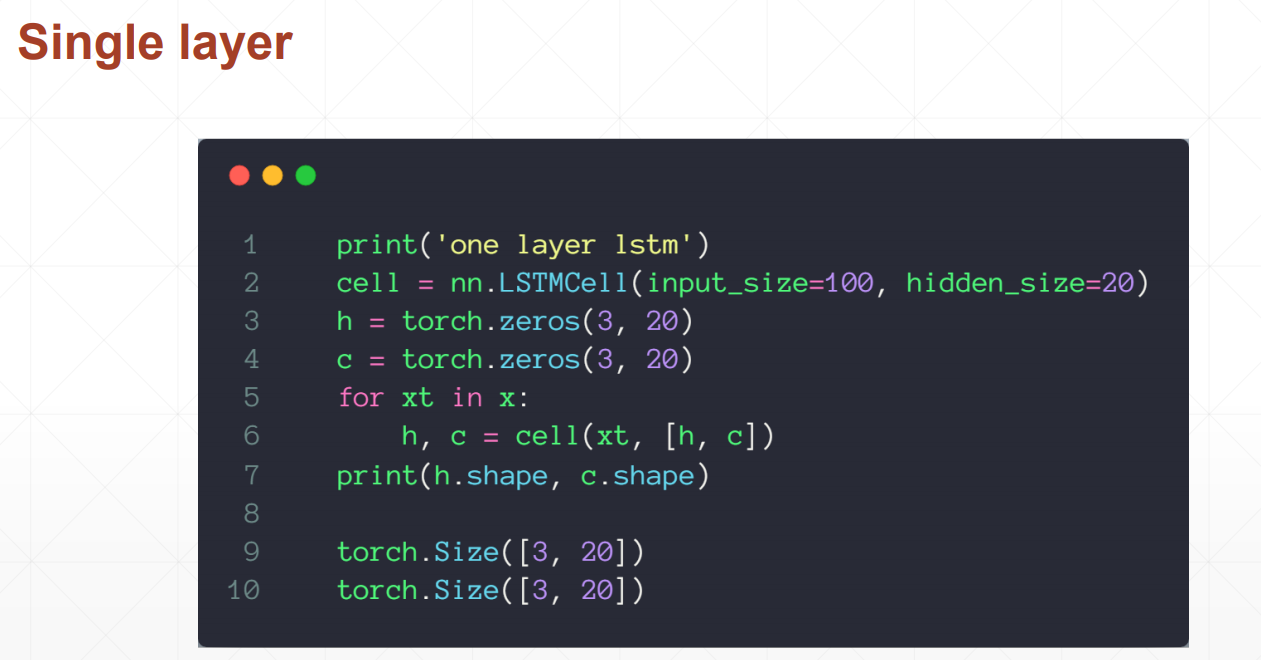
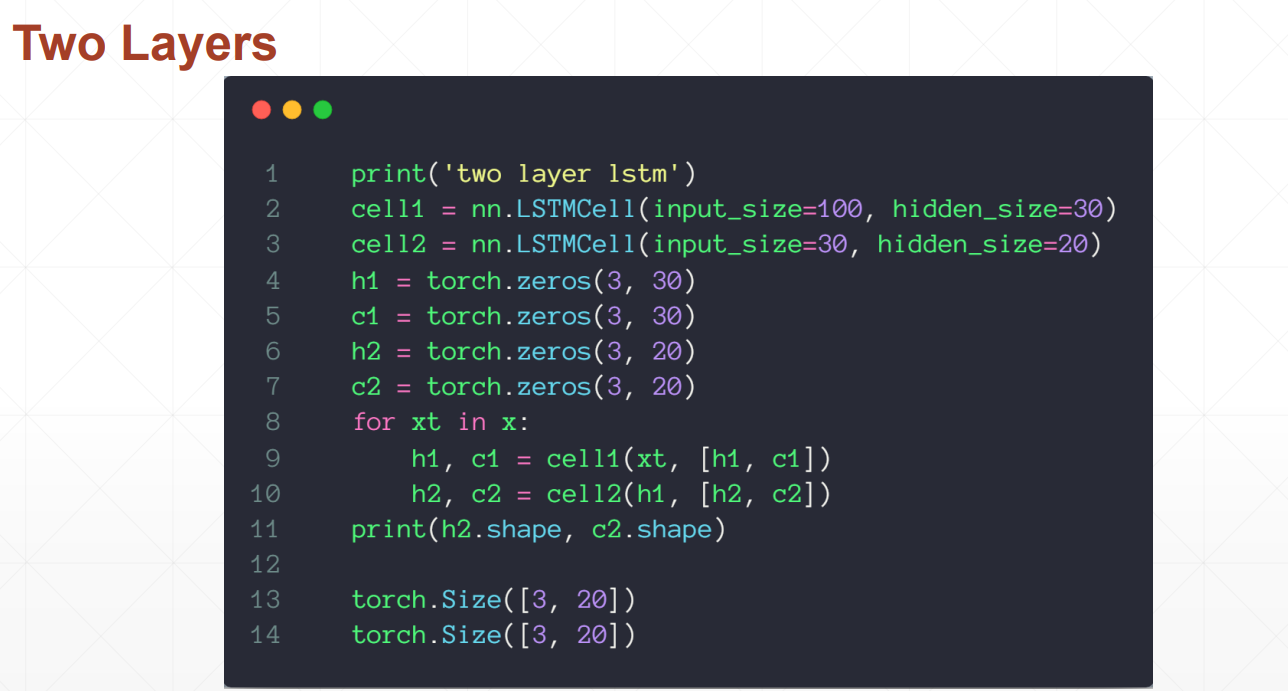
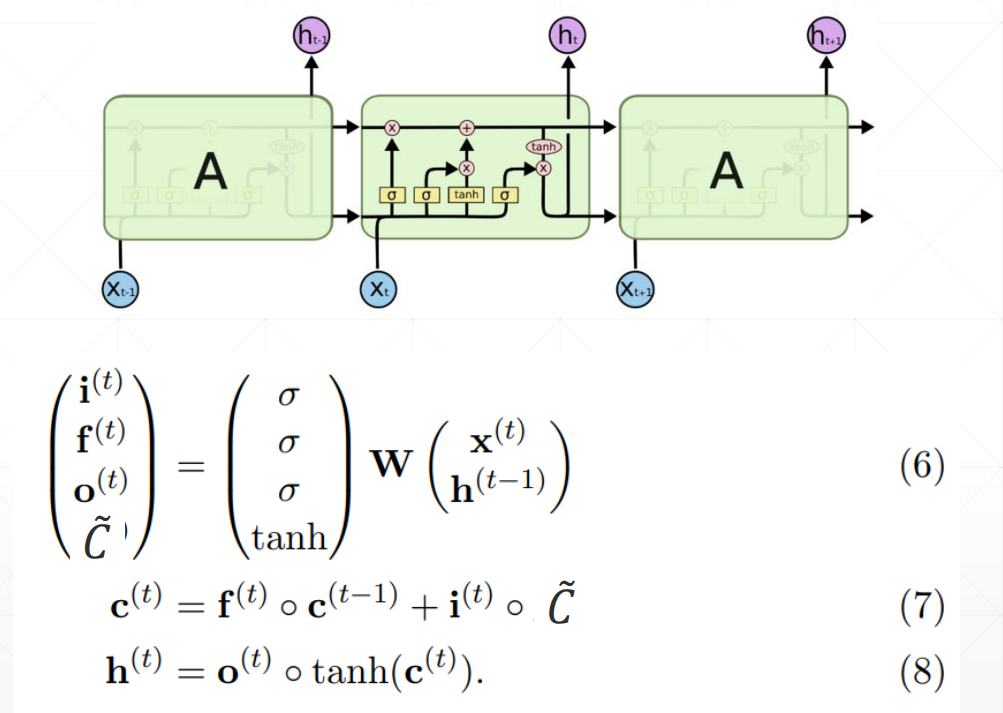
LSTM使用方法

LSTMcell更为灵活的使用方法,可以自定义喂数据的方式
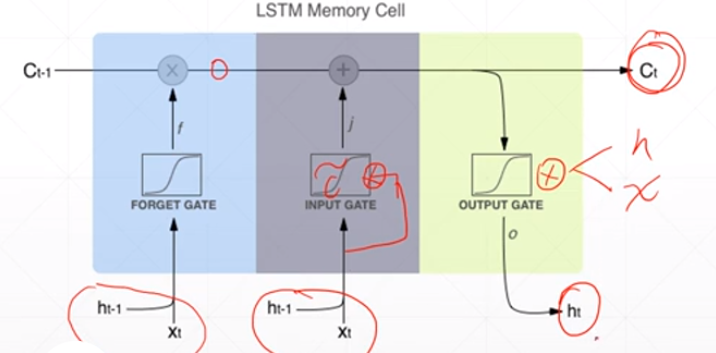
2、输入门
it作为一个开度,将多少信息传入到下一个时间点,有算法决定这个开度;新信息同样也是由ht-1和当前点的xt共同决定的。it是对当前信息的过滤系数,当前信息与开度相乘之后就是经过过滤后输入下一个点的新信息。
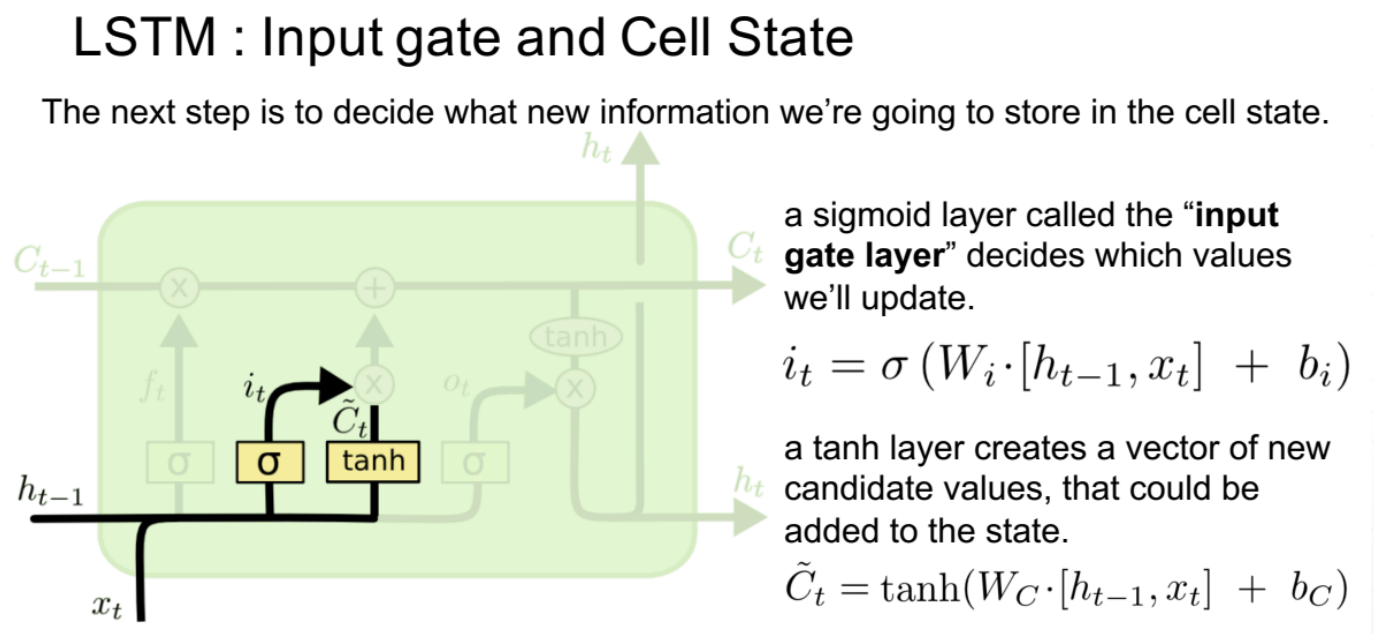
输入门的值

ct是memory,ht是隐藏层的输出
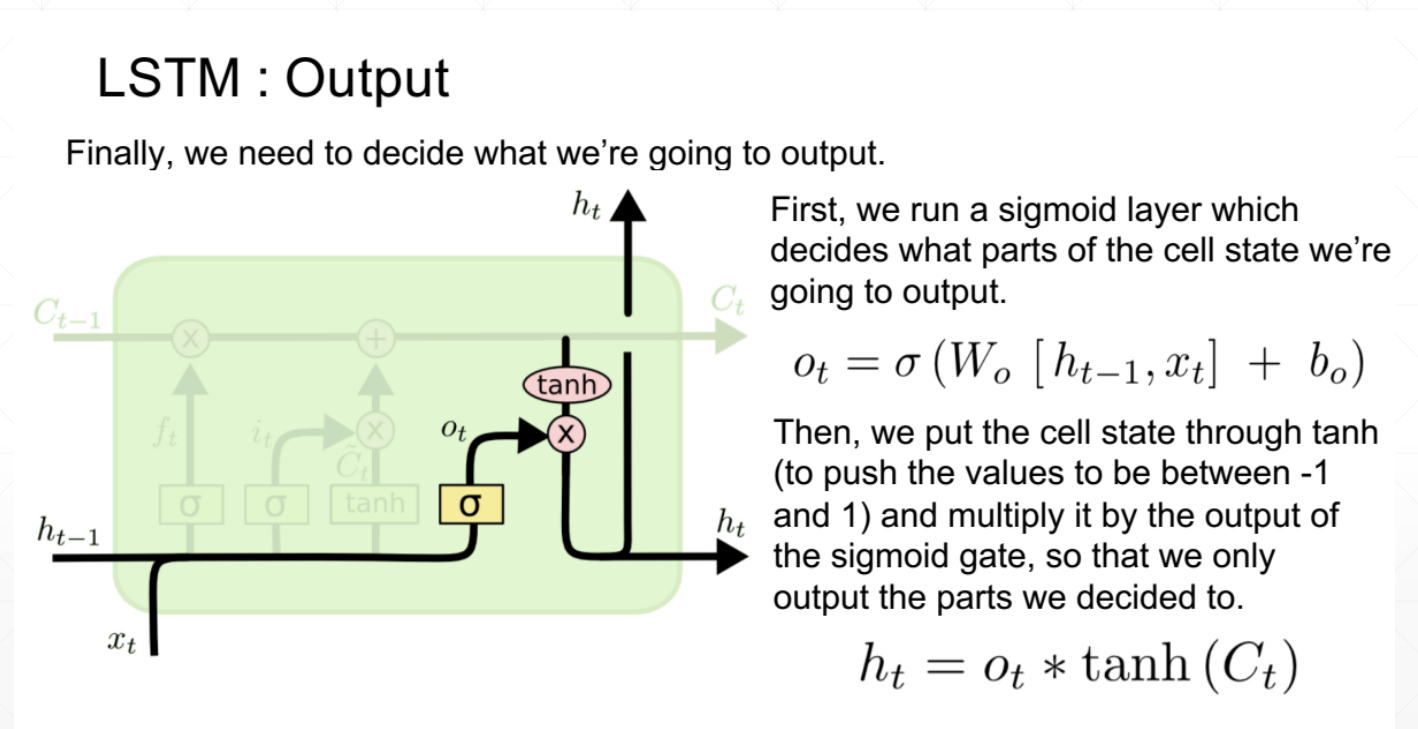
3、输出值
同样是由开度和ct共同决定的,ot作为开度也是由算法决定的
LSTM如何解决梯度离散的问题呢?
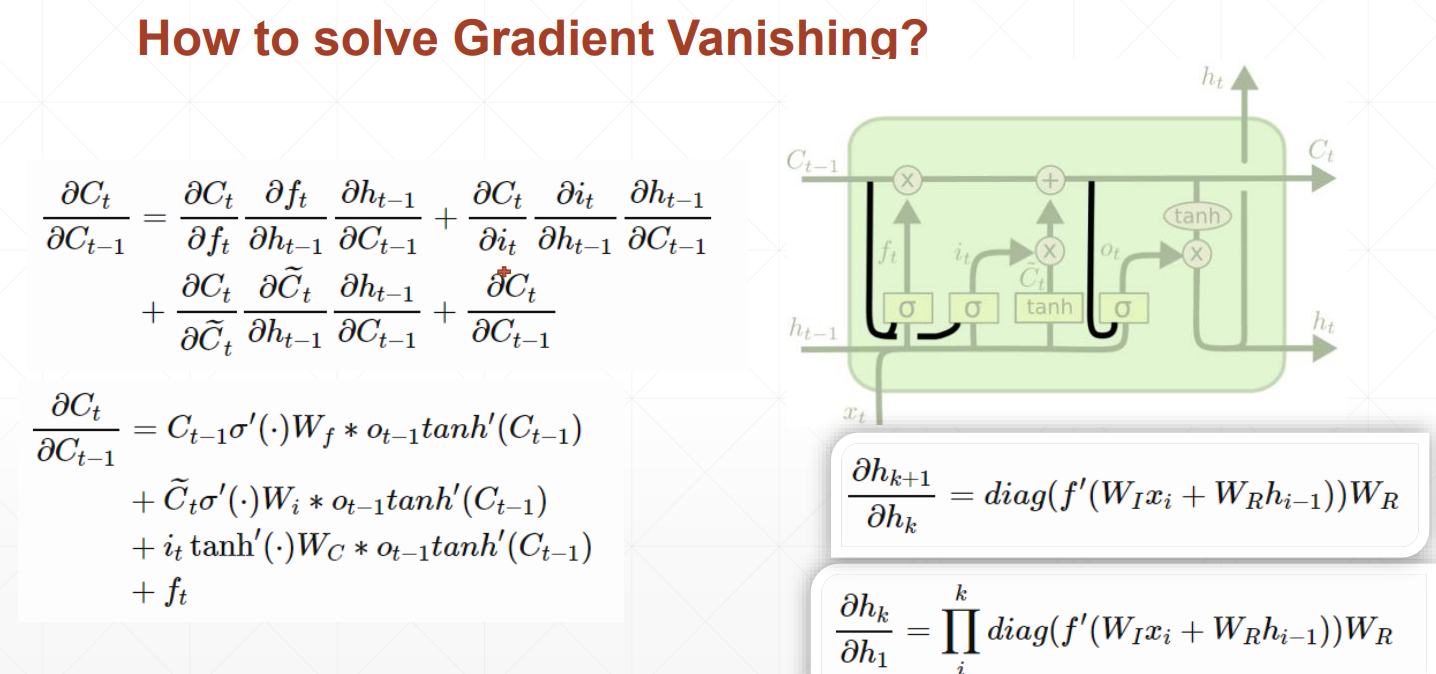
由于存在忘记门、输入门和输出门三个门
当前隐藏层对前一个隐藏层求导时,出现三个值相加的情况,不容易出现都是大或都是小的情况,数值相对可靠,所以效果相对来说更好一些。
LSTM将短期记忆变长,RNN只能记住比较短的时间序列,LSTM就是为了解决短期记忆的问题。
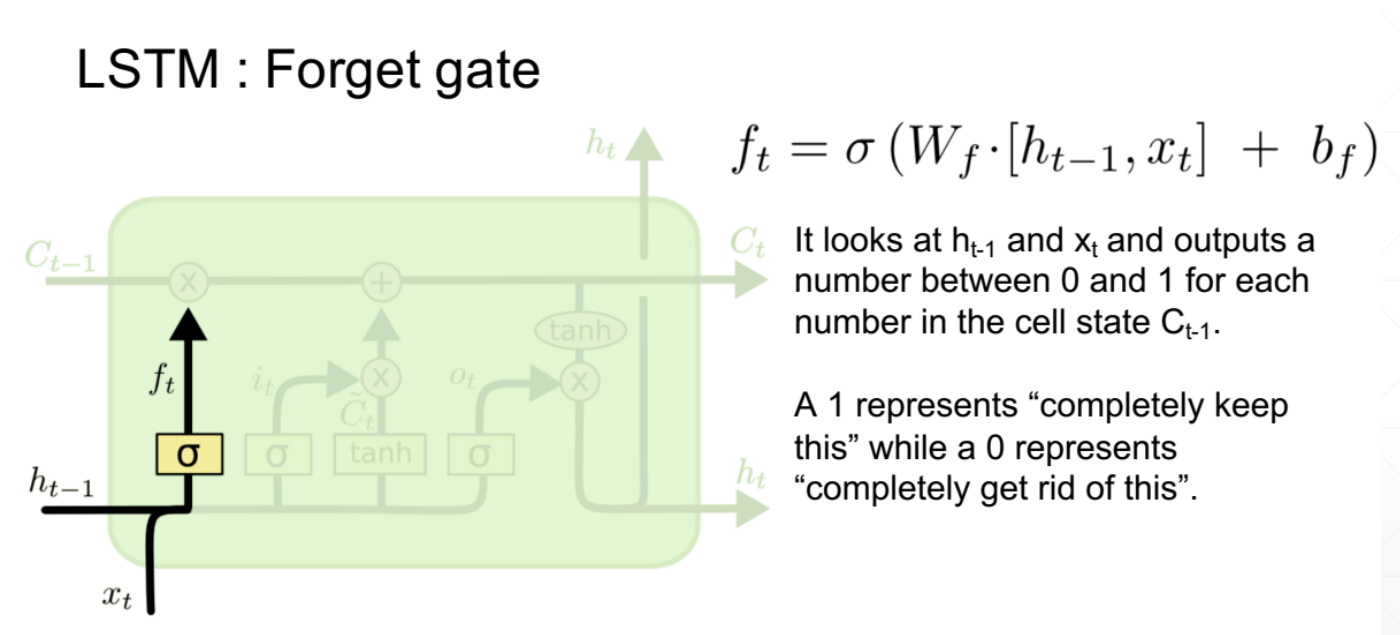
1、忘记门
梯度爆炸
why?

梯度是有WR的k次方乘以其他的一些东西得到的

当WR大于1的时候,k次方会非常大
当WR小于1的时候,k次方会接近于0
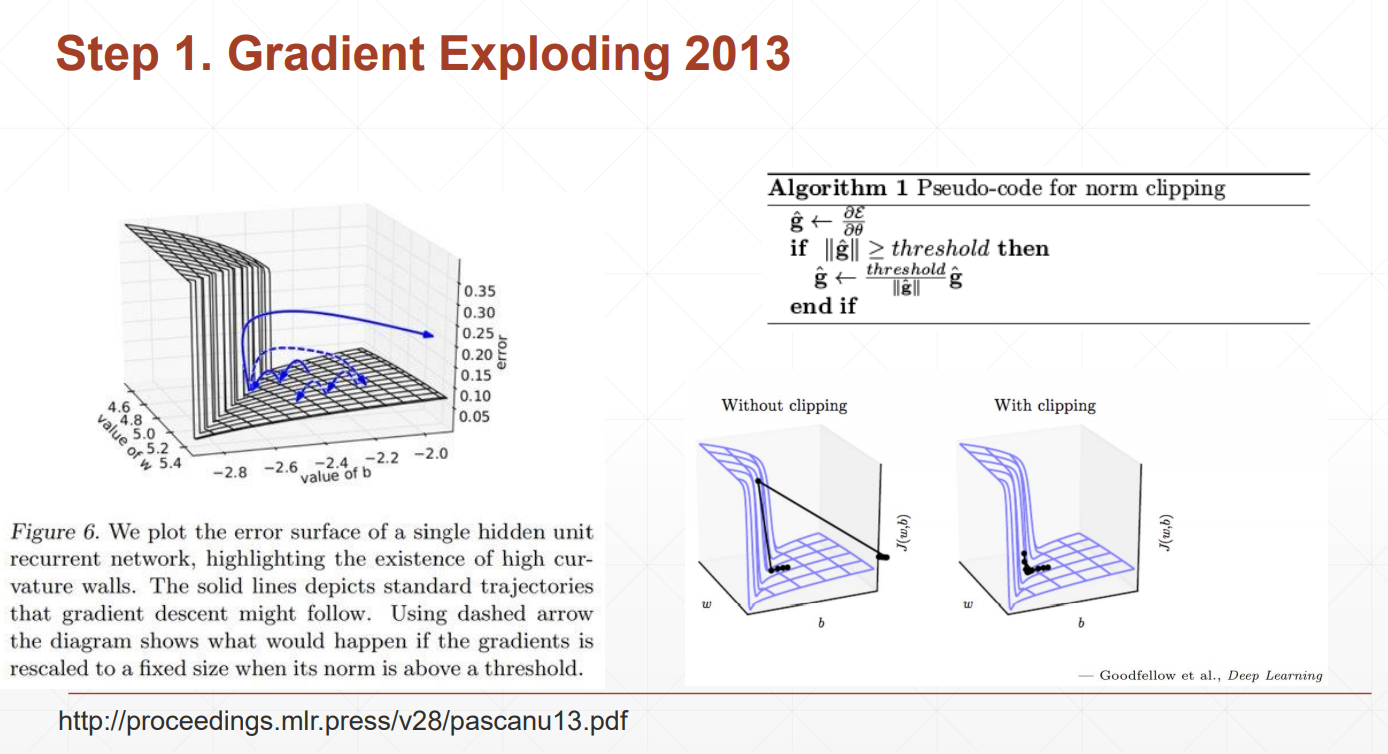
我们的loss本来是逐渐变小的,发生梯度爆炸的loss会突然增大,为了解决这个问题,我们可以检查当前位置的梯度值,如果大于我们设定的阈值,我们将用梯度本身来除以她此刻的模,再乘以阈值,这样使得梯度在设定范围内,且方向不发生变化
Gradient Clipping

查看一下梯度的模,利用clip_grad_norm把梯度的裁剪到10左右
梯度离散:后面隐藏层梯度变化比较大,前面的隐藏层梯度变化很小,长时间得不到更新

out是所有的时间戳上面最后一个memory状态
h是左右一个时间的所有memory状态
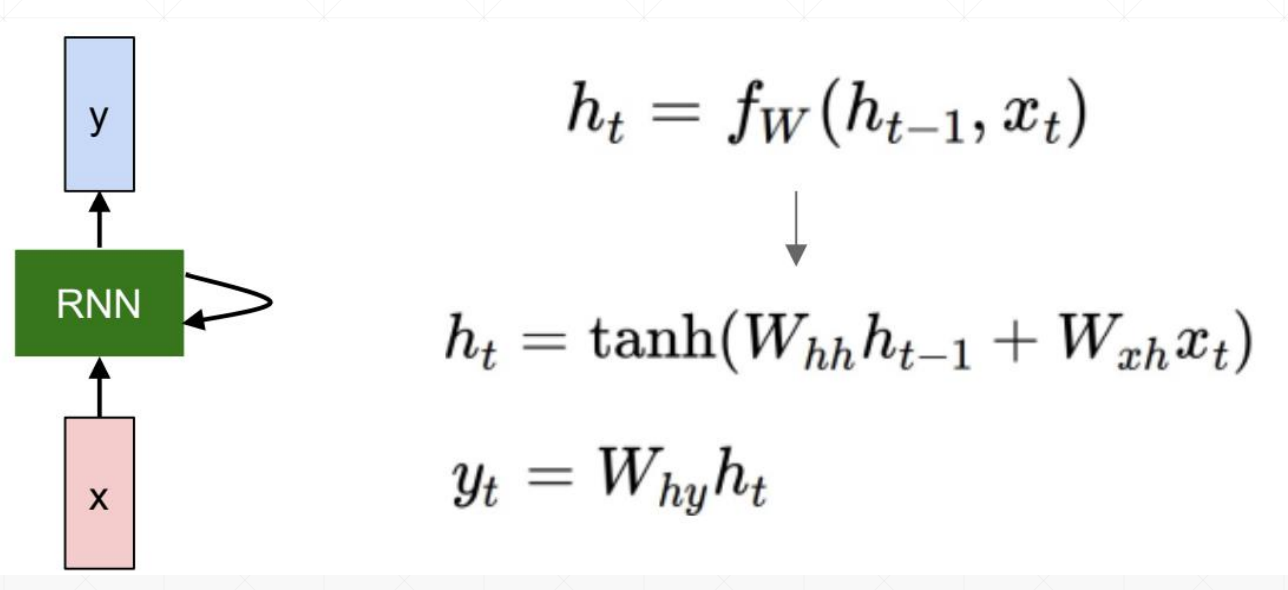
memory的更新方式
How to train?
求导过程略
RNN循环神经网络
RNN跟CNN最大的区别是会根据语境信息更新
时间序列表示方法
pytorch里面并没有支持字符串的功能
one_hot是比较稀疏的、维度高
sequence序列能接受的input shape有两种
[word num, b, word vec]
[b, word num, word vec]
CIFAR—10数据集包括了常见的十类事物的图片
每一类有6000张图片,一共有6万张,其中5万张用来训练,1万张用来测试

数据增强
神经网络对数据的要求非常饥渴,需要贴有标签的大量数据
当数据量有限的时候:1、要减少神经网络的隐藏层;2、Regularization,迫使一部分权值接近于0,让网络的表现更加稳定;3、数据增强,目前的数据量较少,想办法对数据进行变换——旋转、裁剪加噪声等
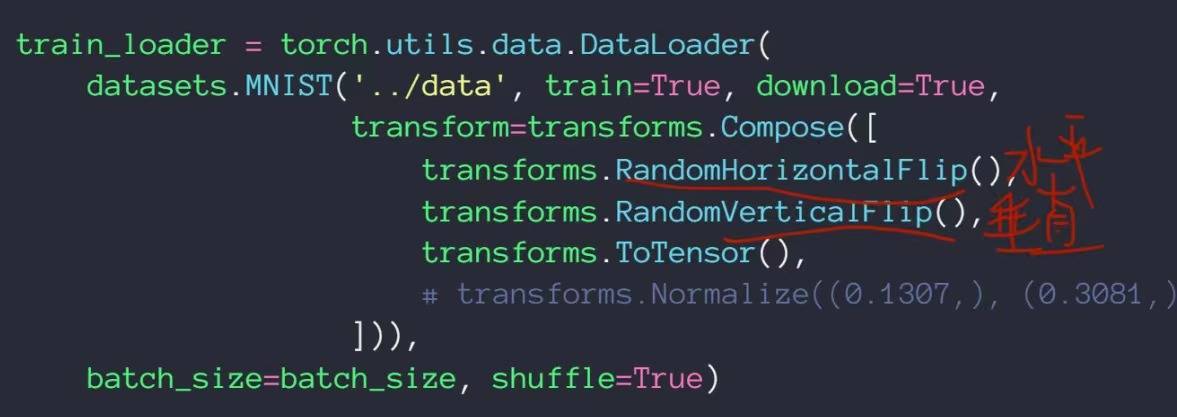
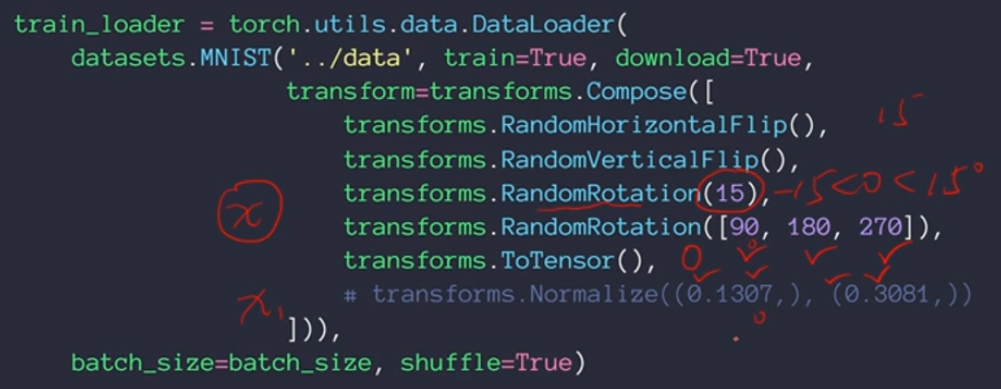
Flip——翻转
可以从水平方向和竖直方向进行翻转,这里增加了random属性,代表翻转是具有随机性的,有可能进行水平翻转,也有可能不翻转,有可能垂直翻转,也有可能不翻转
Rotate——旋转
Scale——缩放
以中心点为标准进行缩放Resize,传入的是list

Crop Part
随机得进行裁剪
transform是torchvision里面自带的包, transform.Compose()可以把一系列翻转、旋转、裁剪和缩放操作组合在一起

Noise——加噪声,用的不多
即使得到了无穷多的数据,由于进行变换后的数据和原本的数据非常接近,所以训练的结果仅仅能得到一个很小的提升
4、save和load

5、train和test状态切换很方便

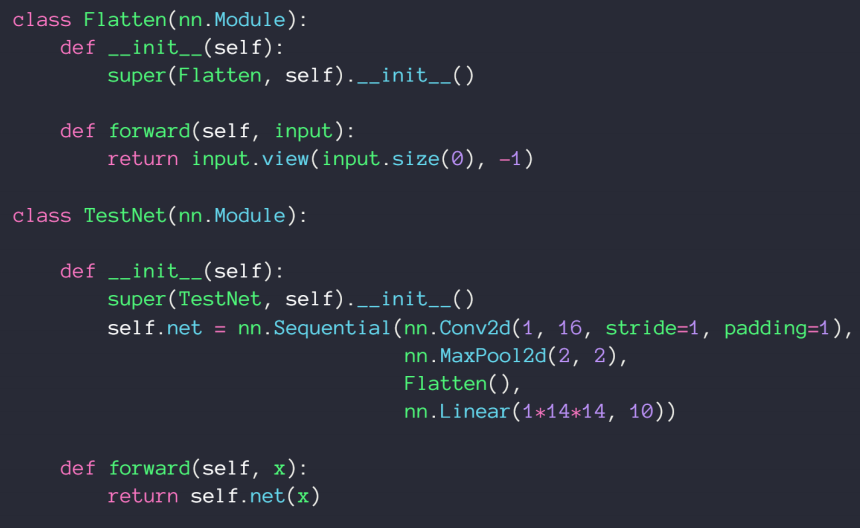
6、implement own layer
由于实际需要定义一个flatten类,我们通过nn.Sequential()来把函数有序排列起来组成我们主要的神经网络结构
7、通过nn.Parameter( )实现自己的参数定义

