java里面是引用传递,还是值传递
User userName = 3;
都是引用传递


java里面是引用传递,还是值传递
User userName = 3;
都是引用传递
数仓的设计:写sql
维度建模的基本概念:
维度表:时间的维度:昨天 地点:星巴克 金钱的维度:两百块 维度表看到的事情比较狭窄,仅仅从某一个方面来看,只能看得到某一块的东西
事实表:没发生的东西,一定不是事实,事实一定是建立在已经发生过的事情上面
昨天我去星巴克喝了一杯咖啡,花了两百块
维度建模的三种方式
星型模型:以事实表为依据,周围很多维度表
订单的分析:用户 货运id 商品id
雪花模型:以事实表为依据 ,很多维度表围绕其中,然后维度表还可能有很多子维度
星座模式:多个事实表有可能会公用一些维度表,最常见的就是我们的省市区的公用
数据宽表的生成
原始数据表: ods_weblog_origin =>对应mr清洗完之后的数据
valid string 是否有效
remote_addr string 访客ip
remote_user string 访客用户信息
time_local string 请求时间 2018-11-20 15:23:25
request string 请求url
status string 响应码
body_bytes_sent string 响应字节数
http_referer string 来源url
http_user_agent string 访客终端信息
求统计 15:00:00 16:00:00访问了多少个页面
select count(1) from ods_weblog_origin where time_local >= 15:00:00 and time_local <= 16:00:00
union all
select count(1) from ods_weblog_origin where time_local >= 16:00:00 and time_local <= 17:00:00
第一步:按照小时进行分组 15 16 17
第二步:分组之后,统计每组里面有多少天记录
select count(1) from ods_weblog_origin group by hour
为了方便我们的统计,将我们的日期字段给拆成这样的几个字段
将我们的ods_weblog_origin 这个表给拆开,拆我们的时间字段
daystr
timestr
month
day
hour
http_referer http://www.baidu.com/hello.action?username=zhangsan http://www.google.com?address=北京 http://www.sougou.com?money=50
ref_host www.baidu.com
ref_path /hello.action
ref_query username
ref_query_id zhangsan
www.baidu.com
www.google.com
www.sougou.com
1、sqoop是什么??
apache开源提供的一个数据导入导出的工具,从关系型数据库导入到hdfs,或者从hdfs导出到关系型数据库等等
从关系型数据库到hdfs 叫做导入
从hdfs到关系型数据库 叫做导出
通过MR的inputformat和outputformat来实现数据的输入与输出,底层执行的全部都是MR的任务,只不过这个mr只有map阶段,没有reduce阶段
说白了只是对数据进行抽取,从一个地方,抽取到另外一个地方
2、sqoop的大的版本
sqoop 1.x 不用安装,解压就能用
sqoop 2.x 架构发生了变化,引入了一个服务端 可以通过代码提交sqoop的任务
一般用sqoop1.x比较多,直接将我们的命令写入到脚本里面去,执行脚本即可
sqoop工具的使用
1、列举出mysql服务器上面所有的数据库
bin/sqoop list-databases --connect jdbc:mysql://192.168.163.30:3306 --username root --password admin
数据采集过来的字段
1、访客ip地址: 58.215.204.118
2、访客用户信息: - -
3、请求时间:[18/Sep/2013:06:51:35 +0000]
4、请求方式:GET
5、请求的url:/wp-includes/js/jquery/jquery.js?ver=1.10.2
6、请求所用协议:HTTP/1.1
7、响应码:304
8、返回的数据流量:0
9、访客的来源url:http://blog.fens.me/nodejs-socketio-chat/
10、访客所用浏览器:Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0
数据的每个字段之间都是用空格隔开的
数据的清洗:
过滤一些静态的数据
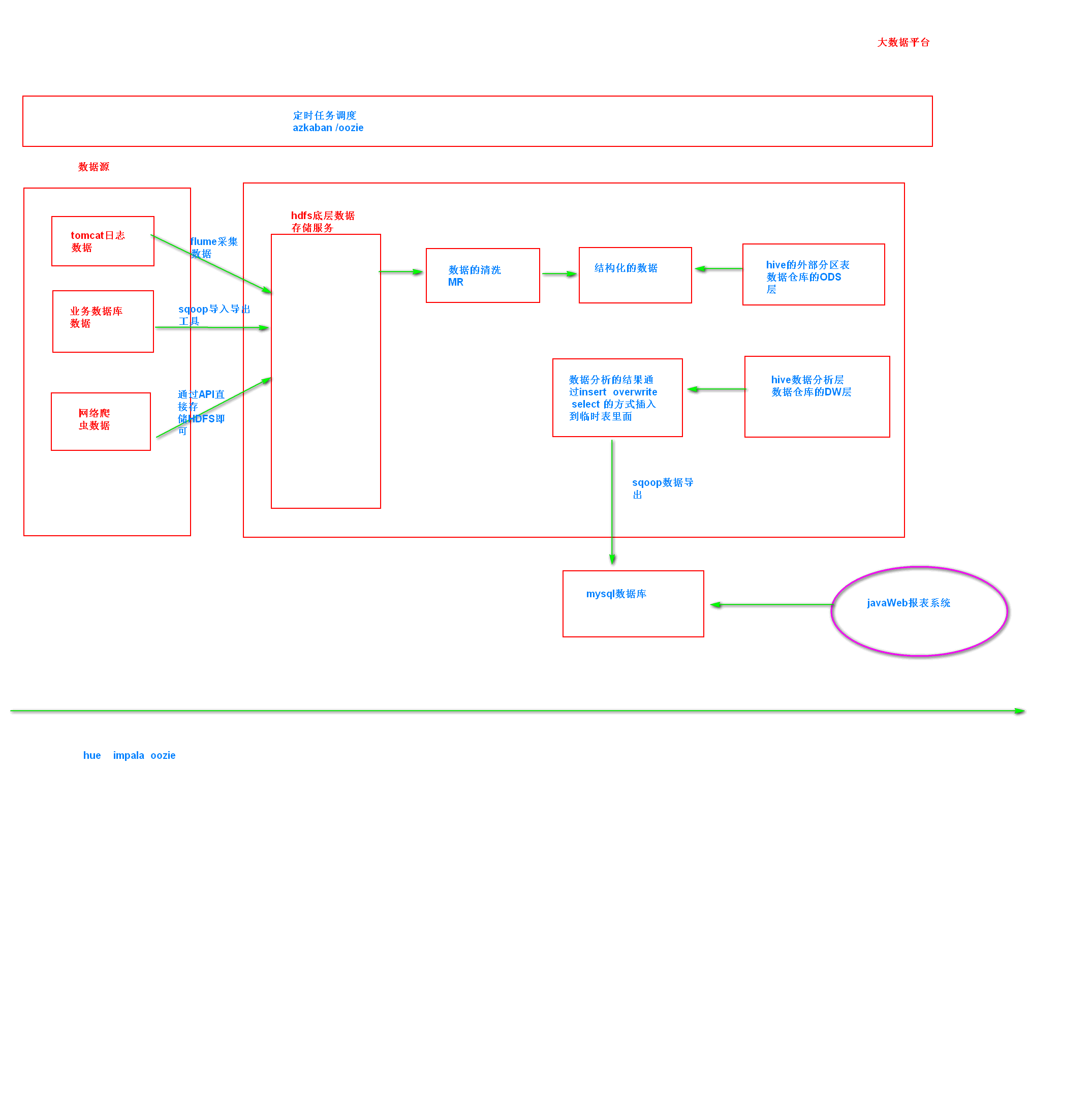
流量日志分析网站整体架构模块
1、数据采集模块
使用flume来进行采集
2、数据的清洗(预处理)
使用mapreduce来进行实现
3、数据的入库
将我们清洗之后结构化的数据全部load到hive的表里面去
4、数据的分析
开发数据统计分析的hql的语句
5、数据的展示
展示我们的结果数据
主要通过echart或者highChart 前端的数据展示框架
6、数据的采集功能
使用flume的tailDirSource 可以按照正则匹配,收集我们某一个文件夹下面的多个不同类型的数据
如果数据这一行数据正在写入,那么过一会儿重试采集,知道数据写入成功
a1.sources = r1
a1.sources.r1.type = TAILDIR
a1.sources.r1.channels = c1
a1.sources.r1.positionFile = /var/log/flume/taildir_position.json
a1.sources.r1.filegroups = f1 f2
a1.sources.r1.filegroups.f1 = /var/log/test1/example.log
a1.sources.r1.filegroups.f2 = /var/log/test2/.*log.*
channel memory channel
sink: hdfs sink 要控制文件的采集的策略,避免hdfs产生大量的小文件
时间长短 文件大小
采集多个文件的话
网站流量模型分析:
分析的是我们网站流量的来源:
广告推广
自然搜索 百度搜索 google搜索
付费搜索 百度竞价排名
直接流量: 直接敲网站的网址
百度药丸:过滤百度广告
网站流量多维度的细分:
访问来源:从什么地方来访问的
访问媒介:访问的新老用户,目标页面等等
网站内容分析:
进入网站首页 ==》 商品分类页 ==》 商品详情页 ==》 订单确认页 ==》 付款页面
不怕你不买,就怕你不来
网站流量转化漏斗分析
流量常见分析分类:
IP:一天之内访问我这个网站不重复IP的个数
一般来说一个IP可能对应多个人
pageView:每打开一个页面,就算一次 pv值
一共访问了多少次页面
unique page view:以用户的cookie来为依据,不同的用户对应不同的cookie。一个用户多次访问网站只算一次
去重之后的访问人数
实际工作当中,如何区分一个用户???
cookie
基础指标:
访问次数:session
人均浏览页数:总的浏览的页数/去重人数
所有的数据流量的统计,都可以借助友盟来实现 在你的网站嵌入一个js代码就行了
流量的来源分析:
主要分析我们的流量从哪些渠道过来的
seo搜索优化
别人都在搜什么东西???
网站统计搜索的关键字排名,然后给小商家提供服务 秋裤
商家服务 订阅淘宝的一些服务
先赚买家的钱,赚卖家的钱
受访分析:网站受到的访问情况
jd.com
sal.jd.com
phone.jd.com
访问域名
受访页面: A.html访问5000次
受访升降榜
热点图
用户视图
访问轨迹:从哪个页面跳转到哪个页面等等
访客分析:
地区运营商
终端详情
新老访客
忠诚度
活跃度
转化路径分析:
分析漏斗模型:
每一步相对于上一步的转化率
每一步相对于第一步的转化率
点击流数据:关注的是用户访问网站的轨迹,按照时间来进行先后区分
基本上所有的大型网站都有日志埋点
通过js的方式,可以获取到你再网站上面点击的所有的链接,按钮,商品,等等,包括你访问的url的链接等等
js埋点,谁来做???专业的前端来做的
埋点收集的数据,都发送到日志服务器 一条日志大概1Kb来算
数据全部在日志服务器
分析用户的点击数据,得到我们的点击流模型
pageView模型:重视的是每一个页面受到的访问情况,每访问一个页面,就算一条记录
visit模型:重视的是每一个session会话内的访问情况,这次会话内,哪个页面进来,哪个页面出去,进入时间,出去时间
package cn.itcast.sshxcute;
import net.neoremind.sshxcute.core.ConnBean;
import net.neoremind.sshxcute.core.SSHExec;
import net.neoremind.sshxcute.exception.TaskExecFailException;
import net.neoremind.sshxcute.task.impl.ExecCommand;
public class XcuteExcute {
public static void main(String[] args) throws TaskExecFailException {
ConnBean connBean = new ConnBean("192.168.52.120", "root", "123456");
//获取SSHExec用于执行我们的shell命令
SSHExec sshExec = SSHExec.getInstance(connBean);
//连接我们的linux服务器
sshExec.connect();
//执行linux命令
//CustomTask 是一个抽象类,获取抽象类两种方式 ,要么就找子类,要么就找我们这个抽象类有没有
//提供什么方法,返回它本身
ExecCommand execCommand = new ExecCommand("echo 1 >> /export/servers/helloworld.txt");
sshExec.exec(execCommand);
//断开连接
sshExec.disconnect();
}
}
sqoop导入导出是一个离线处理的工具
底层使用的都是MR的程序
有没有什么工具,可以实现实时的抽取数据
canal 通过解析binlog可以实现实时的数据抽取
flume 自定义source 代码在github上面 也可以实现近似实时的数据抽取
streamSet 比较强大,可以实现实时的抽取数据
下去调研了解以上三个工具实现实时的抽取
使用--where来实现增量的导入
bin/sqoop import \
--connect jdbc:mysql://192.168.163.30:3306/userdb \
--username root \
--password admin \
--table emp \
--incremental append \
--where "create_time > '2018-06-17 00:00:00' and is_delete='1' and create_time < '2018-06-17 23:59:59' " \
--target-dir /sqoop/incement2 \
--check-column id \
--m 1
--last-value 2018-06-17 00:00:00
2018-06-18 01:00:00 产生一条数据
2018-06-18 02:00:00
sqoop的数据的导出:
导出:从hdfs到关系型数据库
bin/sqoop export \
--connect jdbc:mysql://192.168.163.30:3306/userdb \
--username root --password admin \
--table emp_out \
--export-dir /sqoop/emp \
--input-fields-terminated-by ","
导出数据的时候,如果导出到一半,报错了怎么办????
一般都是创建mysql的临时表 如果临时表导入成功,再往目的表里面导入
sqoop的job 就是将我们的导入导出到命令,保存起来,下次可以直接调用,没有必要,写脚本就好了
2、列举出数据库下面所有的数据库表
bin/sqoop list-tables --connect jdbc:mysql://192.168.163.30:3306/azkaban --username root --password admin
3、导入mysql表到hdfs上面来 但是没有指定hdfs的导入路径
bin/sqoop import --connect jdbc:mysql://192.168.163.30:3306/userdb --username root --password admin --table emp -m 1
4、入mysql表到hdfs上面来 指定hdfs的路径
bin/sqoop import --connect jdbc:mysql://192.168.163.30:3306/userdb --username root --password admin --table emp -m 1 --delete-target-dir --target-dir /sqoop/emp
5、导入数据到hdfs上面来,指定hdfs的路径,并且指定导出字段之间的分隔符
bin/sqoop import --connect jdbc:mysql://192.168.163.30:3306/userdb --username root \
--password admin --table emp -m 1 --delete-target-dir --target-dir /sqoop/emp2 \
--fields-terminated-by '\t'
6、导入数据到hive表里面来
需要将hive-exec包放到sqoop的lib目录下面来
hive建表:
create external table emp_hive(id int,name string,deg string,salary int ,dept string) row format delimited fields terminated by '\001';
bin/sqoop import --connect jdbc:mysql://192.168.163.30:3306/userdb --username root \
--password admin --table emp -m 1 --delete-target-dir --target-dir /sqoop/emp2 \
--fields-terminated-by '\001' --hive-import --hive-table sqooptohive.emp_hive --hive-overwrite
如果mysql表字段比hive字段多,那么hive里面就会丢几个字段
如果mysql表字段比hive字段少,那么hive里面就会有字段为null值
7、导入数据到hive里面来,并且自动创建hive表
bin/sqoop import --connect jdbc:mysql://192.168.163.30:3306/userdb \
--username root --password admin --table emp_conn --hive-import -m 1 \
--hive-database sqooptohive;
8、导入数据子集
bin/sqoop import \
--connect jdbc:mysql://192.168.163.30:3306/userdb \
--username root --password admin --table emp_add \
--target-dir /sqoop/emp_add -m 1 --delete-target-dir \
--where "city = 'sec-bad'"
9、通过sql语句查找导入hdfs里面来
使用sql语句来进行查找是不能加参数--table
并且必须要添加where条件,
并且where条件后面必须带一个$CONDITIONS 这个字符串,
并且这个sql语句必须用单引号,不能用双引号
bin/sqoop import --connect jdbc:mysql://192.168.163.30:3306/userdb \
--username root --password admin \
-m 1 --delete-target-dir \
--target-dir /sqoop/emp_conn \
--query 'select phno from emp_conn where 1=1 and $CONDITIONS'
10、增量的导入
只导入我们部分需要的数据
现在时间2018-11-20 02:30:00 导入数据时间 2018-11-19 00:00:00 2018-11-19 23:59:59
全量导入,数据太多,对数据库压力比较大
id
1
2
3
4
5
记录下来,第一次id到了3
增量的导入
bin/sqoop import \
--connect jdbc:mysql://192.168.163.30:3306/userdb \
--username root \
--password admin \
--table emp \
--incremental append \
--check-column id \
--last-value 1202 \
-m 1 \
--target-dir /sqoop/increment
如何解决增量导入的问题??
每个表都会有三个固定的字段
create_time
update_time
is_delete
operator
create_time 2018-11-18 20:12:32
update_time 2018-11-19 20:12:32
如何解决导入增量的问题
每个数据都会有一个创建时间,可以根据我们的创建时间来判断是否是我们前一天的数据
如何解决导入减量数据的问题???
什么是减量数据????删除掉的数据 数据不是做真删除
做假删除,其实就是改变了一些数据的状态,数据的更新时间同步改变
银行客户 13859687451
变更手机号 13896541235
所有的减量数据都转化为变更数据来处理
第一个:涉及到数据的变更问题,
变更数据一定有更新时间 每天导入数据的时候,需要根据创建时间和更新时间来一起判断
第一条数据 create_time 2018-11-19 12:23:45
第二条数据 update_time 2018-11-19 15:23:45
根据两个条件来同时进行判断,满足任意一个,都要将数据导入过来
id create_time update_time
1 2018-11-15 23:45:15 2018-11-15 23:45:15
1 2018-11-15 23:45:15 2018-11-28 23:45:15
group by id
如何解决减量问题??
如何解决变更问题???
都是根据create_time update_time 来联合进行判断
多个表关联时,最好拆分成小段,避免大sql(无法控制中间Job)
大表join大表的时候:所有的调优原则就是尽量减少输入数据量
不过滤空ID
INSERT OVERWRITE TABLE jointable;
SELECT a.* FROM nullidtable AS a
JOIN ori AS b
ON a.id=b.id;
以A表数据为准,B表当中没有空id的数据全部都join不上
过滤空Id
INSERT OVERWRITE TABLE jointable;
SELECT a.* FROM (
SELECT * FORM nullidtable
WHERE id is NOT NULL) AS a
JOIN ori AS b
ON a.id=b.id;
以A表为主表,join B表,但是A表中过滤了很大一部分id为null的数据,数据量变少
mysql行转列怎么做
笛卡尔积
任何时候都要避免笛卡尔积
join的时候一定要避免无效的on条件
分区裁剪,列裁剪
只取我们用到的分区,只取我们用到的字段
不要写select * 对于分区表,一定要带上分区条件
SELECT a.id
FROM bigtable a
LEFT JOIN ori b
ON a.id = b.id
WHERE b.id <= 10;
先过滤再join
SELECT a.id
FROM ori a
LEFT JOIN bigtable b
ON (a.id <= 10 AND a.id = b.id);
SELECT a.id
FROM bigtable a
RIGHT JOIN (
SELECT id
FROM ori
WHERE id <= 10) b
ON a.id = b.id;
load载入数据是文本文件的格式
想向orc表中加载数据需要用到insert into
存储压缩比
ORC > Parquet > textFile
查询速度对比
ORC > TextFile > Parquet
存储与压缩相结合:
存储格式与压缩方式没关系
实际工作当中,一般存储格式与压缩方式都会一起使用
log_orc 2.8M 因为orc格式的数据中使用了默认自带的zlib压缩方式
注意:就算orc存储格式不带任何压缩方式,也会比行式存储的文件大小小,这就是列式存储的优势
实际工作当中一般分析之后,存储数据的一些临时表都会使用orc的存储格式,压缩方式用snappy
定时任务的工具
为了保证我们的任务正常的在每天凌晨执行,我们需要借助一些任务调度工具
azkaban oozie ariflow zeus
造成学习困难
redis memory cache
数据的脱敏 将一些敏感信息,全部进行加密
手机号 银行卡号 银行卡余额
原始数据八个字段,经过处理之后,只要五个字段,并且第一个字段进行加密
采集数据的时候就要进行处理
使用flume的自定义拦截器,来实现将数据进行脱敏
实现数据采集之前就已经处理好了,数据采集到hdfs上面来之后,全部都已经进行脱敏了
flume的failover机制
可以实现将我们的文件采集之后,发送到下游,下游可以通过flume的配置,实现高可用
数据的脱敏 将一些敏感信息,全部进行加密
手机号 银行卡号 银行卡余额
原始数据八个字段,经过处理之后,只要五个字段,并且第一个字段进行加密
采集数据的时候就要进行处理
使用flume的自定义拦截器,来实现将数据进行脱敏
实现数据采集之前就已经处理好了,数据采集到hdfs上面来之后,全部都已经进行脱敏了
tomcat的日志数据 catalina.out
nginx的日志 access.log
flume监控文件的内容变化,将文件里面新增的数据全部收集到hdfs上面去
source 使用exec source
多级agent串联
flume的监测:
flume比较脆弱,一旦抛异常,就会停止工作
只能够手动重启 什么时候flume会死掉
第一个:什么情况表示flume死掉了???
如果源数据,没有变少,flume可能死掉了
如果目的地数据,没有增多,flume也可能死掉了
可以写一个脚本,定时的执行检测,检测源数据有没有减少,检测目的数据有没有增多
杀掉flume,重新启动
也可以使用failover的机制
多长时间采集一次
文件多大采集一次
文件的采集策略 多长时间采集一次,文件多大采集一次
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
# 定义文件多大的时候采集一次
a1.sinks.k1.hdfs.rollInterval = 3
a1.sinks.k1.hdfs.rollSize = 20
a1.sinks.k1.hdfs.rollCount = 5
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
你们flume的采集频率是怎么设置的??
问的是不是就是如何设置flume的采集频率
设置两种控制策略
文件127.9M的时候采集一次
第二种:两个小时滚动一次
第七天课程:
离线项目的处理流程
flume:flume是一个分布式的日志采集的工具,说白了就是用来采集数据的
可以从文件,文件夹,http协议等都能各个地方
使用比较简单,配置即可
flume的运行机制:三个组件构成
source:数据采集组件,对接我们的源数据
channel:管道 数据的缓冲区,连接source与sink,将我们的source与sink进行打通
sink:对接我们目的地的数据,数据保存到哪里去都是这个sink说了算
这三个组件共同构成一个flume的运行的实例,运行的实例叫做agent
可以理解为channel就是一个管子,将我们source采集的数据,都搬到sink目的地去
第一个案例:flume采集网络端口的数据
9、动态分区
适用于我们的分区表数据
set hive.exec.dynamic.partition = true;
set hive.exec.dynamic.partition.mode = nonstrict;
set hive.exec.max.dynamic.partitions = 1000;
set hive.exec.max.dynamic.partitions.pernode = 100;
set hive.exec.max.created.files = 100000;
set hive.error.on.empty.partition = false;
不用动态分区的时候插入数据,需要手动的指定分区值
insert overwrite table ori_partitioned_target PARTITION (p_time='20130812')
select id, time, uid, keyword, url_rank, click_num, click_url from ori_partitioned;
使用动态分区,不用手动指定分区直,但是select字段的时候,最后面的字段,一定要是分区字段
分区字段的值不能是中文
INSERT overwrite TABLE ori_partitioned_target PARTITION (p_time)
SELECT id, time, uid, keyword, url_rank, click_num, click_url, p_time
FROM ori_partitioned;
10、数据倾斜
如何控制map的个数,以及如何控制reduce的个数
reduce当中map的个数以及reduce个数
map个数:block块大小有关,一个block块对应一个maptask
reduce个数: job.setNumReduceTasks(10) 手动指定
是不是map个数越多越好???不是
maptask是不是越少越好??? 也不是
如果有一个block块,里面有几千万条记录,map处理比较复杂,
如何增加map个数以及如何减少map个数
第一个问题:如何减少map个数
一个,调整block块的大小
二个。合并小文件
set mapred.max.split.size=112345600;
set mapred.min.split.size.per.node=112345600;
set mapred.min.split.size.per.rack=112345600;
set hive.input.format= org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
这个参数表示执行前进行小文件合并,前面三个参数确定合并文件块的大小,大于文件块大小128m的,按照128m来分隔,小于128m,大于100m的,按照100m来分隔,把那些小于100m的(包括小文件和分隔大文件剩下的),进行合并。
大于128M的文件,按照128M来进行切分
100到128按照100进行切分
切分剩下的小文件,进行合并
如何增加map个数
可以使用distributed by来先将文件计算一遍,打散成很多的小文件
set mapreduce.job.reduces =10;
create table a_1 as
select * from a
distribute by rand(123);
将我们的表数据,均匀的打散成十个小文件,这样就最少会有10个maptask
reduce个数的设置:
方法一调整 估算reduce个数
(1)每个Reduce处理的数据量默认是256MB
hive.exec.reducers.bytes.per.reducer=256123456
(2)每个任务最大的reduce数,默认为1009
hive.exec.reducers.max=1009
(3)计算reducer数的公式
N=min(参数2,总输入数据量/参数1)
方法二直接调整
)调整reduce个数方法二
在hadoop的mapred-default.xml文件中修改
设置每个job的Reduce个数
set mapreduce.job.reduces = 15;
11、执行计划
使用执行计划,查看我们的hql的运行的过程
12、并行的执行
有些hql是无关联的,可以并行的一起执行
set hive.exec.parallel=true; //打开任务并行执行
set hive.exec.parallel.thread.number=16; //同一个sql允许最大并行度,默认为8。
select * from a union select * from b
13。hive的严格模式
三个作用
1:笛卡尔积不能执行
2:order by需要带limit字段 order by只能有一个reduce
3:分区表要带上分区字段 减少输入的数据量
14、jvm的重用
container执行完了maptask或者reducetask之后,不要释放资源
继续给下一个maptask或者reduetask进行执行
15、推测执行
关闭map端和reduce端的推测执行
16、数据的压缩
参见压缩那一章