目标权重参数
class_weight & min_weight_fraction_leaf
在银行要 判断“一个办了信用卡的人是否会违约”,就是是vs否(1%:99%)的比例。这种分类状况下,即便模型什么也不 做,全把结果预测成“否”,正确率也能有99%。因此我们要使用class_weight参数对样本标签进行一定的均衡,给 少量的标签更多的权重,让模型更偏向少数类,向捕获少数类的方向建模。
有了权重之后,样本量就不再是单纯地记录数目,而是受输入的权重影响了,因此这时候剪枝,就需要搭配min_ weight_fraction_leaf这个基于权重的剪枝参数来使用。另请注意,基于权重的剪枝参数(例如min_weight_ fraction_leaf)将比不知道样本权重的标准(比如min_samples_leaf)更少偏向主导类。如果样本是加权的,则使 用基于权重的预修剪标准来更容易优化树结构,这确保叶节点至少包含样本权重的总和的一小部分。
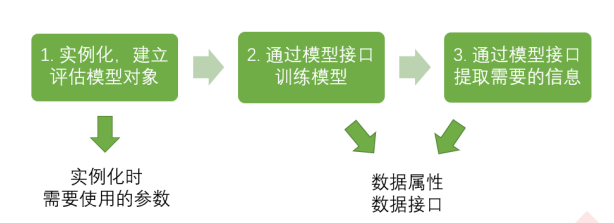
重要的属性和接口
sklearn中许多算法的接口都是相似的,比如说我们之前已经用到的fit和score,几乎对每个算法都可以使用。除了 这两个接口之外,决策树最常用的接口还有apply和predict。

如果你的数据的确只有一个特征,那必须用reshape(-1,1)来给 矩阵增维;如果你的数据只有一个特征和一个样本,使用reshape(1,-1)来给你的数据增维。
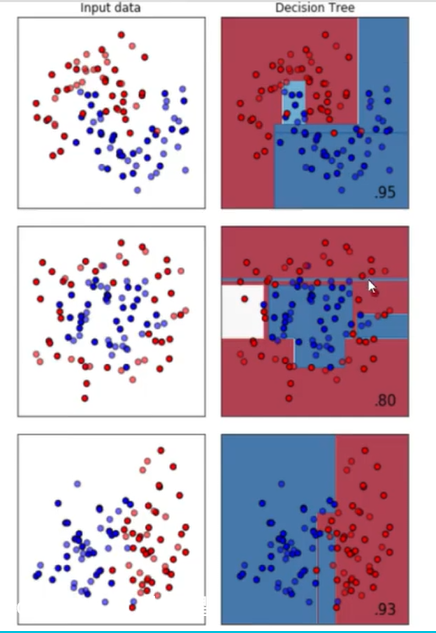
决策树模型天生对环形数据没有良好的训练效果。
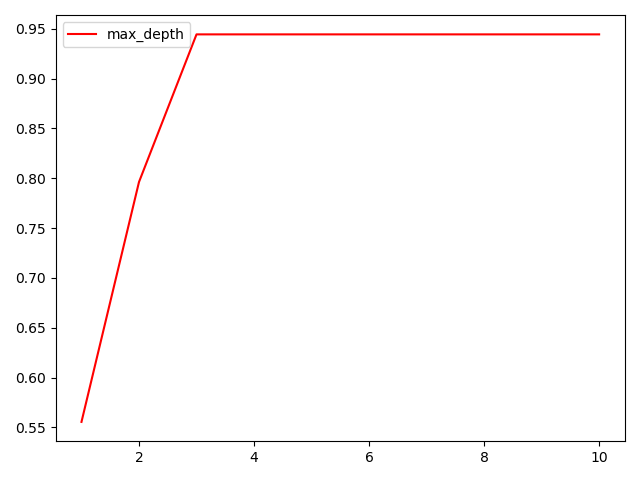
第一个是月亮型数据集、第二个是环形数据集、第三个是对半分数据集。分类树天生不擅长环形数据。每个模型都有自己的决策上限,所以一个怎样调整都无法提升 表现的可能性也是有的。当一个模型怎么调整都不行的时候,我们可以选择换其他的模型使用,不要在一棵树上吊 死。顺便一说,最擅长月亮型数据的是最近邻算法,RBF支持向量机和高斯过程;最擅长环形数据的是最近邻算法和高斯过程;最擅长对半分的数据的是朴素贝叶斯,神经网络和随机森林。