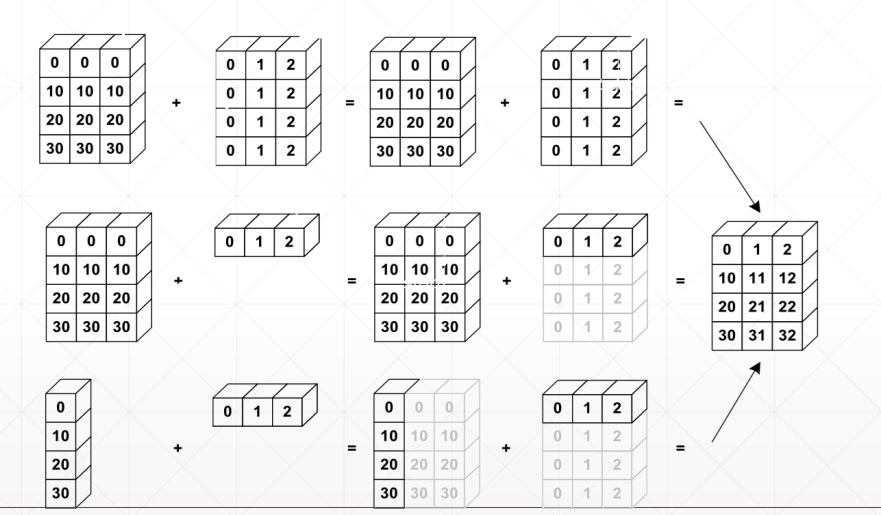
从最小维度开始匹配,我们默认越高维度越相似,而小维度上各有各的不同

[32, 32]给每行每列加一个base基底;
[3, 1, 1]相等于是给每个通道都加个值;
[1, 1, 1, 1]像素点增加了一个值


从最小维度开始匹配,我们默认越高维度越相似,而小维度上各有各的不同
[32, 32]给每行每列加一个base基底;
[3, 1, 1]相等于是给每个通道都加个值;
[1, 1, 1, 1]像素点增加了一个值
why broadcasting
(1)本身有现实意义;
(2)可以节省内存消耗
什么情况下需要将broadcasting?
match from last dim!
·如果当前的dim=1,扩展相同的维度
·如果其他地方没有维度,可以添加这一个模块,然后扩展成相同维度
·否则,则不能进行传播
broadingcasting
(1)expand
(2)without copying data
key idea

repeat接口
repeat传参的参数是拷贝的次数
转置操作
Expand/repeat
Expand——broadcasting仅仅是把数据进行了传播,节约内存
仅仅局限于从1开始扩展,如果是从3拓展的话,是不可行的,会报错
Repeat——实实在在的数据拷贝
squeeze、unsqueeze
for example
数据的存储、维度顺序非常重要,需要时刻谨记
索引与切片
4、rand、rand_like、randint
rand随机生成在[0, 1]的数值
rand_like是先把rand生成的数组读取出来再喂给rand函数
randint需要给出最大值、最小值和shape
创建tensor
(1)从numpy进行导入
(2)从list里面导入
小写的tensor括号里接收的是现有数据,而大写Terson、FloatTensor里面接受的是形状,也可以接受现成的数据,括号里用中括号时表示现成的数据,括号时输入的形状
Dim1
一般会用在bias、线性层的输入
Dim2
一般用在batch,当输入多张图片时,第一个数字是图片的个数,第二个是打平图片之后的一维点数
Dim3
适合RNN的文字处理
Dim4
适合CNN
第一个数字是图片的个数,第二个数字是图片的通道,通道为1是灰色图像,通道为3的是菜色图像,后两位数字28*28是minis数据集的长和宽
pytorch中的数据类型

没有对string的支持内键
how to denote string
(1)One-hot并不体现语义
(2)Embedding—word2vec
核实数据类型
数据类型
(1)标量
回归问题实战
(1)先计算总损失值
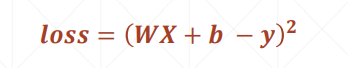
(2)然后计算w和b的偏导,进而更新梯度值

需要四步:
(1)load data
(2)build model
(3)train
(4)test
Non-linear Factor
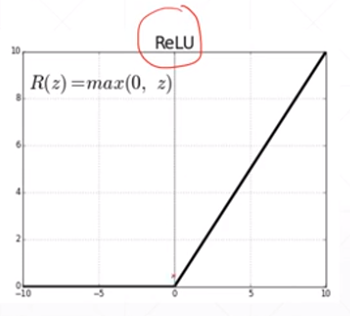
加入激活函数之后

pred既有线性表达能力,还有非线性的表达能力

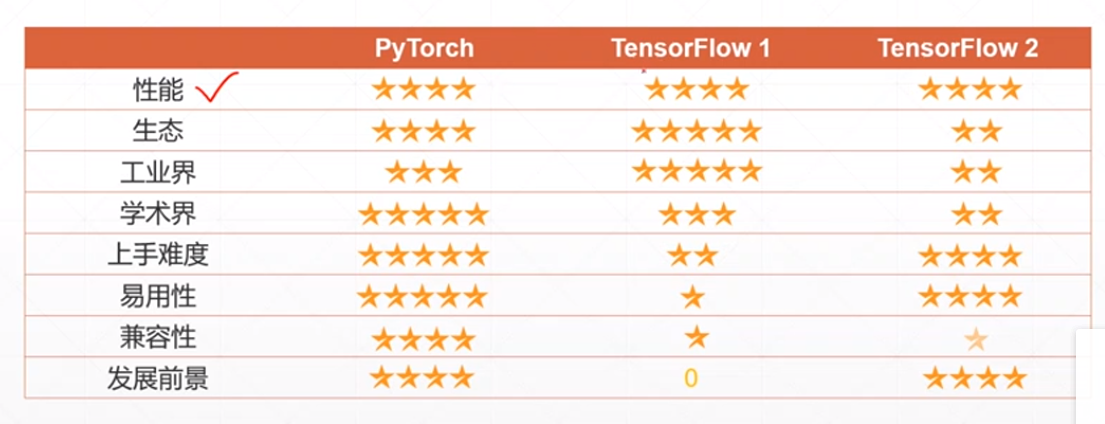
pytorch的功能:
(1)CPU加速;
没有显卡,用不了cuda
(2)自动求导*非常重要,因为深度学习本质上就是在利用梯度下降法来求最优解;
(3)常用网络层


静态图:
define——>run
在最开始就需要定义好公式,给定输入值,得到输出值,而且在运行的过程中无法进行调整

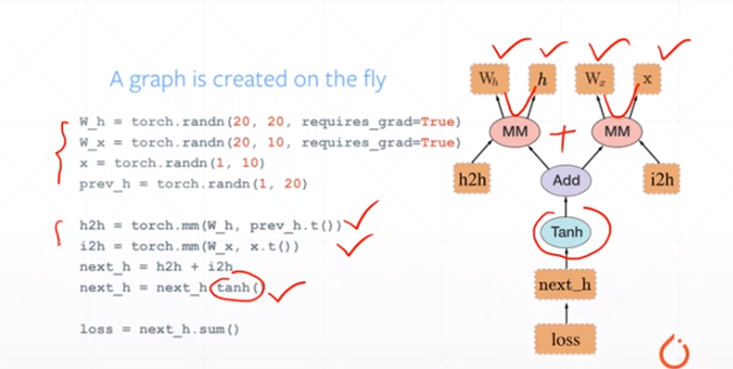
动态图:
可以随时调整公式
linear Regression——我们要估计连续函数的值;
logistic Regression——在上述linear regression的基础上增加了一个激活函数,把y的空间压缩到0-1的范围,0-1可以表示一个概率
classification——所有的可能性概率之和为1
梯度下降法